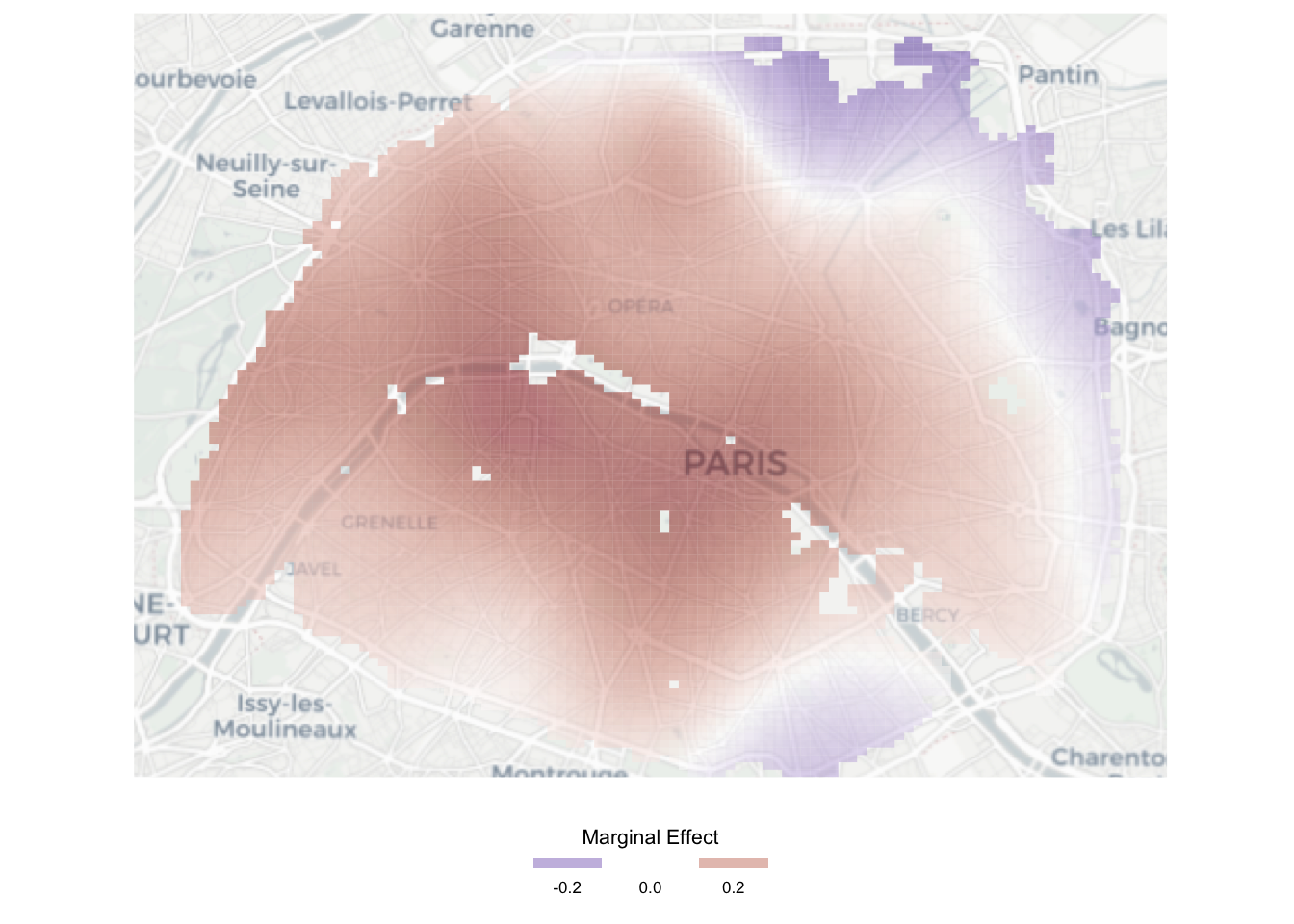
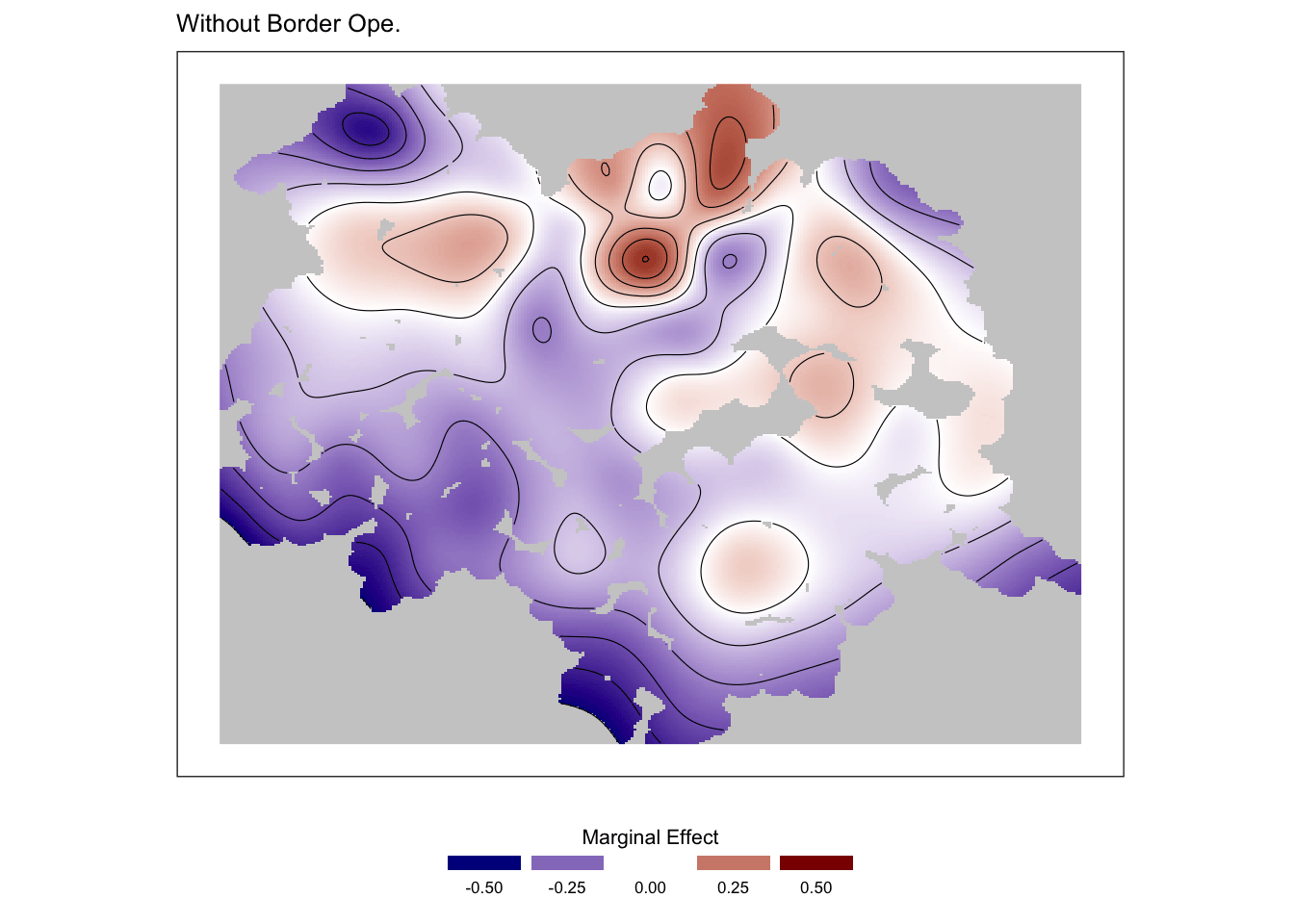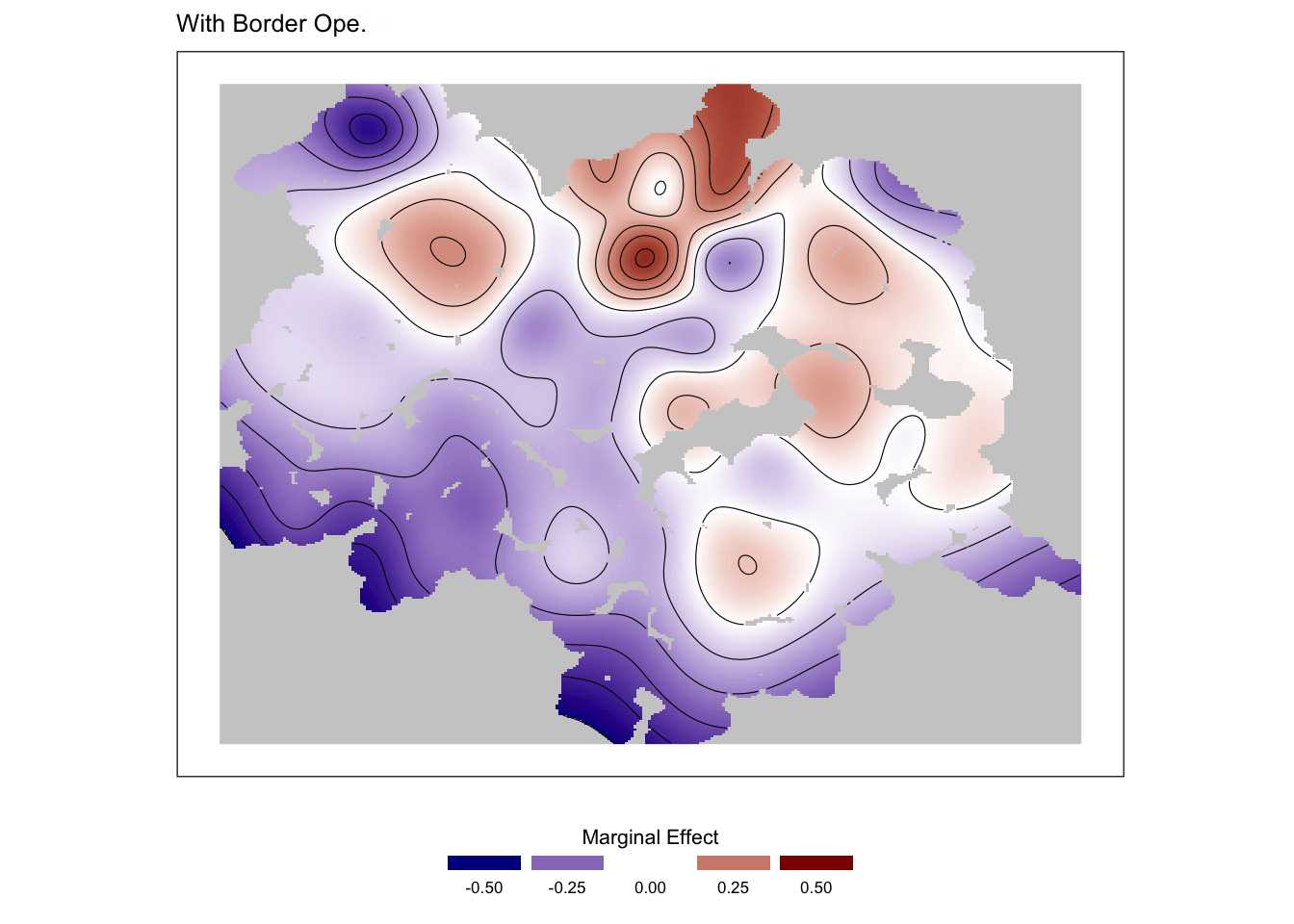
Modèle de prix
Cette rubrique reprend l’ensemble des éléments qui permettent de construire le modèle de prix implémenté
dans le cadre du travail de thèse. Il repose sur les données DV3F, et utilise les modèles additifs
généralisés (GAM) pour introduire les coordonnées spatiales.
Principe général
Le modèle de prix se base sur les données DV3F à propos des ventes de logements uniques en France
métropolitaine, avec un travail spécifique sur les valeurs aberrantes. Ces données permettent de
calibrer la modélisation des prix, exploitant les modèles additifs généralisés (GAM dans la suite).
Plusieurs méthodes alternatives ont été testées, méthode des moindres carrés (OLS), régression
géographiquement pondérée (GWR) notamment. Le GAM est l'option qui minimise l’erreur moyenne. Des
méthodes alternatives telles que random forest ou catboost n’ont pas été étudiées du fait
de notre
souhait de conserver un modèle transparent. Ce modèle calibré permet ensuite d’estimer la valeur de
marché pour les logements présents dans les Fichiers Fonciers. Faute de données disponibles en Alsace et
Moselle dans DV3F, ces territoires sont exclus de l'estimation.
L’estimation est réalisée sur le premier trimestre de chaque année. Elle est menée au niveau de la zone
d’emploi, maille homogène pour l’analyse des marchés immobiliers.
Dans un premier temps, nous détaillons les filtres imposés pour la base DV3F, puis détaillons
l’implémentation ainsi que son principe général. Enfin, nous détaillons les paramètres retenus pour
calibrer le modèle.
Filtrage des données
Les filtres sur la bases DV3F sont nombreux et ont pour principal objectif de supprimer les observations
aberrantes, non pertinentes, ou avec des variables manquantes. L’objectif est de réduire en amont
l’influence de ces observations dans la qualité de l’estimation.
Filtres DV3F
Les principaux filtres appliqués à DV3F sont au nombre de quatre et concerne le type de transaction, le
type de logement, le nombre de locaux associés à la mutation et les observations présentant des
informations manquantes.
- La première opération consiste à ne retenir que les observations concernant des ventes, incluant les
ventes et les VEFA. On supprime ainsi les échanges et les adjudications car ces transactions ne
correspondent pas à des transactions monétaires.
- La seconde opération filtre les mutations concernant plusieurs logements. Dans un cas où une
mutation se rapporte à deux logements ou plus, il n’est pas possible d’observer la répartition du
coût de transaction entre chaque logement. De fait, il semble difficile d’établir un prix de marché,
à partir d’informations parcellaires. De plus, les transactions à propos de plusieurs logements
peuvent répondre à des logiques de marché différentes. De fait, nous choisissons de ne pas retenir
les ventes de logements par lot.
- On ne retient pas non plus les logements sociaux. En effet, ces derniers répondent à des logiques
économiques différentes, notamment car le vendeur peut-être obligé de respecter un plafonnement du
prix de ventes aux occupants (avec un prix potentiellement sous-évalué par rapport au marché). Il
nous semble donc que ces logements ne sont pas pertinents dans le cadre de notre modélisation.
- Nous supprimons toutes les observations avec une valeur mal spécifiée concernant la surface
habitable, la surface de dépendance, le type de logement, ou l’année de construction. Ces variables
composent le cœur de notre modèle d’estimation. Pour l’année de construction, nous retenons les
opérations qui ont une année de construction supérieure à 1300. Cette valeur est toutefois
arbitraire.
Filtres IQR
Une fois les premiers filtres appliqués, nous appliquons une seconde phase de filtrage afin de supprimer
les valeurs aberrantes. Toutefois, comme cette notion se définit au niveau local (un bien à 9 000 euros
par mètre carré est une valeur aberrante en zone détendue mais pas à Paris), nous choisissons
d’appliquer la détection de ces valeurs aberrantes au niveau local. De fait, nous choisissons de
supprimer les observations qui ne respectent pas les règles issues de l’IQR (suppression des
observations inférieures au premier quartile moins 1,5 fois l'intervalle interquartile et supérieures au
troisième quartile plus 1,5 fois l'intervalle interquartile).
Pour les municipalités avec peu d’observations, la méthode ne supprime pas d’observations. Concernant les
municipalités avec de nombreuses informations, la méthode supprime uniquement les observations
aberrantes, que ce soit par excès ou par défaut.
Filtres finaux
Enfin, les derniers filtres appliqués lors de la modélisation sont menés au niveau national : nous ne
retenons que les opérations qui sont supérieures à 50 k€, et inférieures à 10 M€. Ainsi, on s’assure une
cohérence grande, avec une réduction des valeurs potentiellement aberrantes.
Implémentation du GAM
L’implémentation du GAM sur les données disponibles est assez simple, car nous retenons comme variables
explicatives le prix au mètre carré (choisi pour avoir une plus grande cohérence), la surface du bien,
la surface des dépendances associées, ainsi que l’âge du bâti au moment de la vente.
Principe général du GAM
Le GAM permet de répondre aux problématiques de sur-apprentissage (over-fitting) et
sous-apprentissage
(under-fitting) par définition optimale de la transformation de variable. Utilisant le maximum de
vraisemblance restreinte (Restricted Maximum Likelihood, REML), le modèle définit de manière
endogène la
transformation optimale de variable à adopter. L’opérateur doit spécifier les baseline smooth,
classes
de fonctions pour transformer la variable en question. Dans le cas où le degré de liberté est fixé à 1,
alors la transformation de variable appliquée est une transformation linéaire. Dans le cas où la valeur
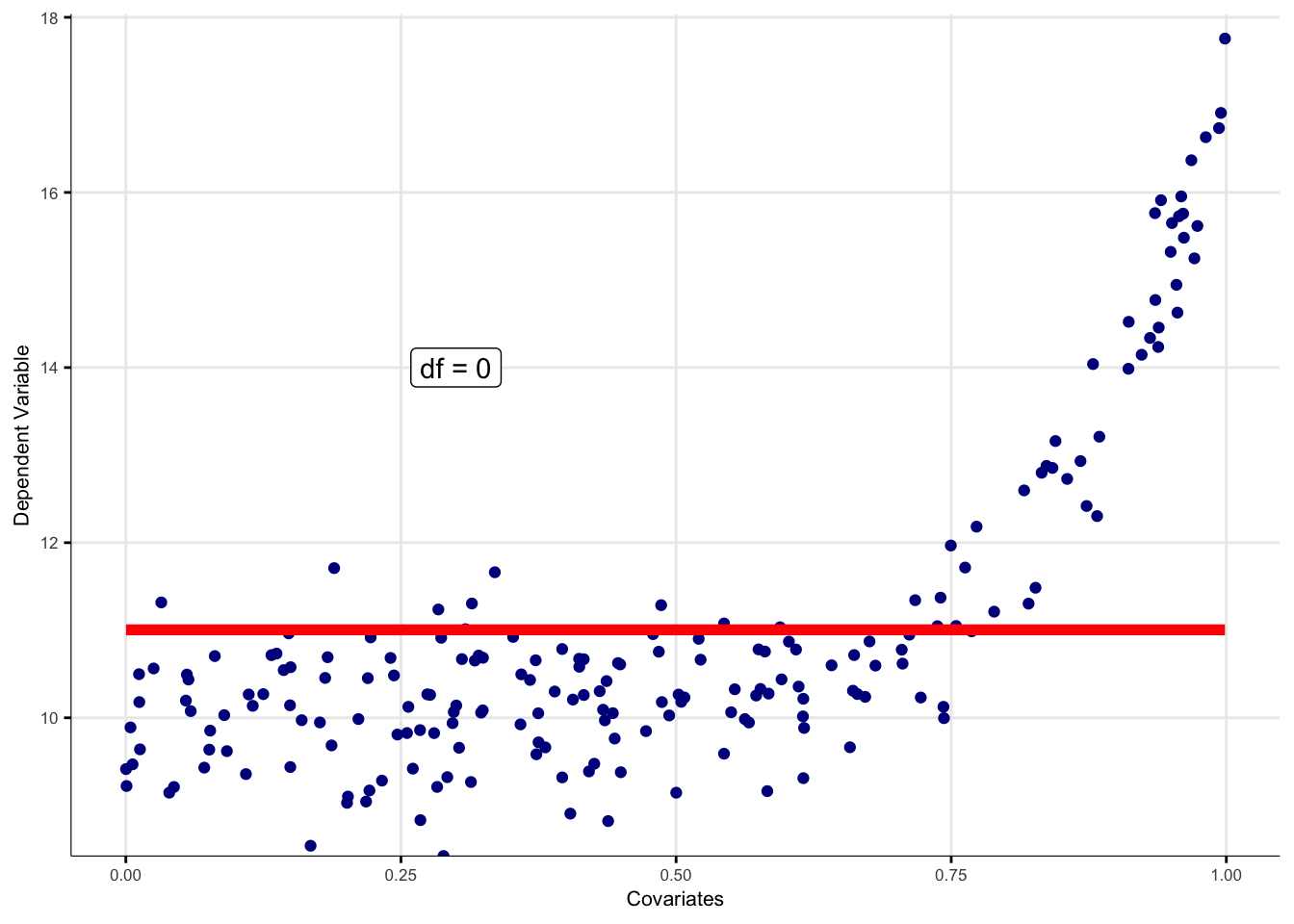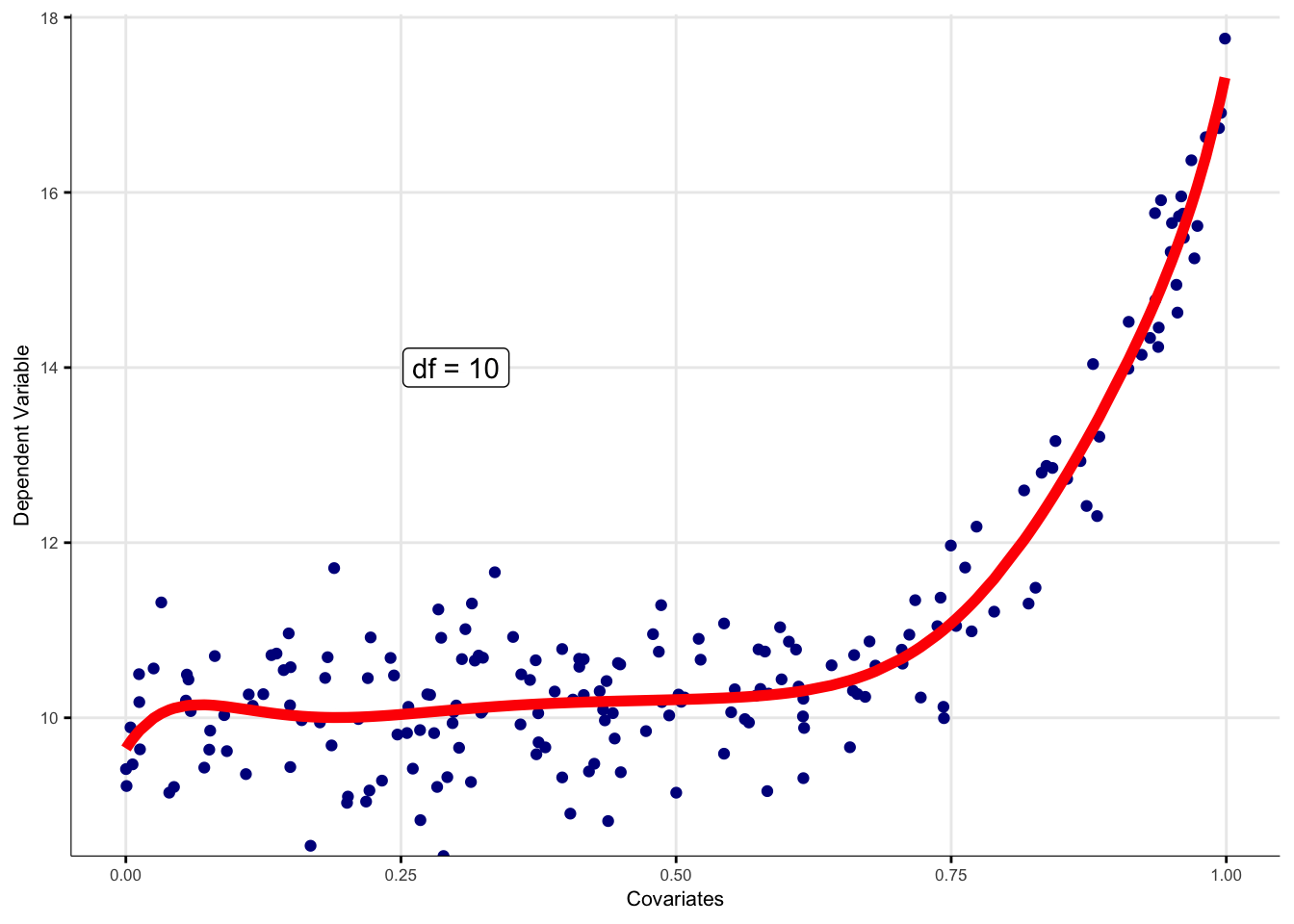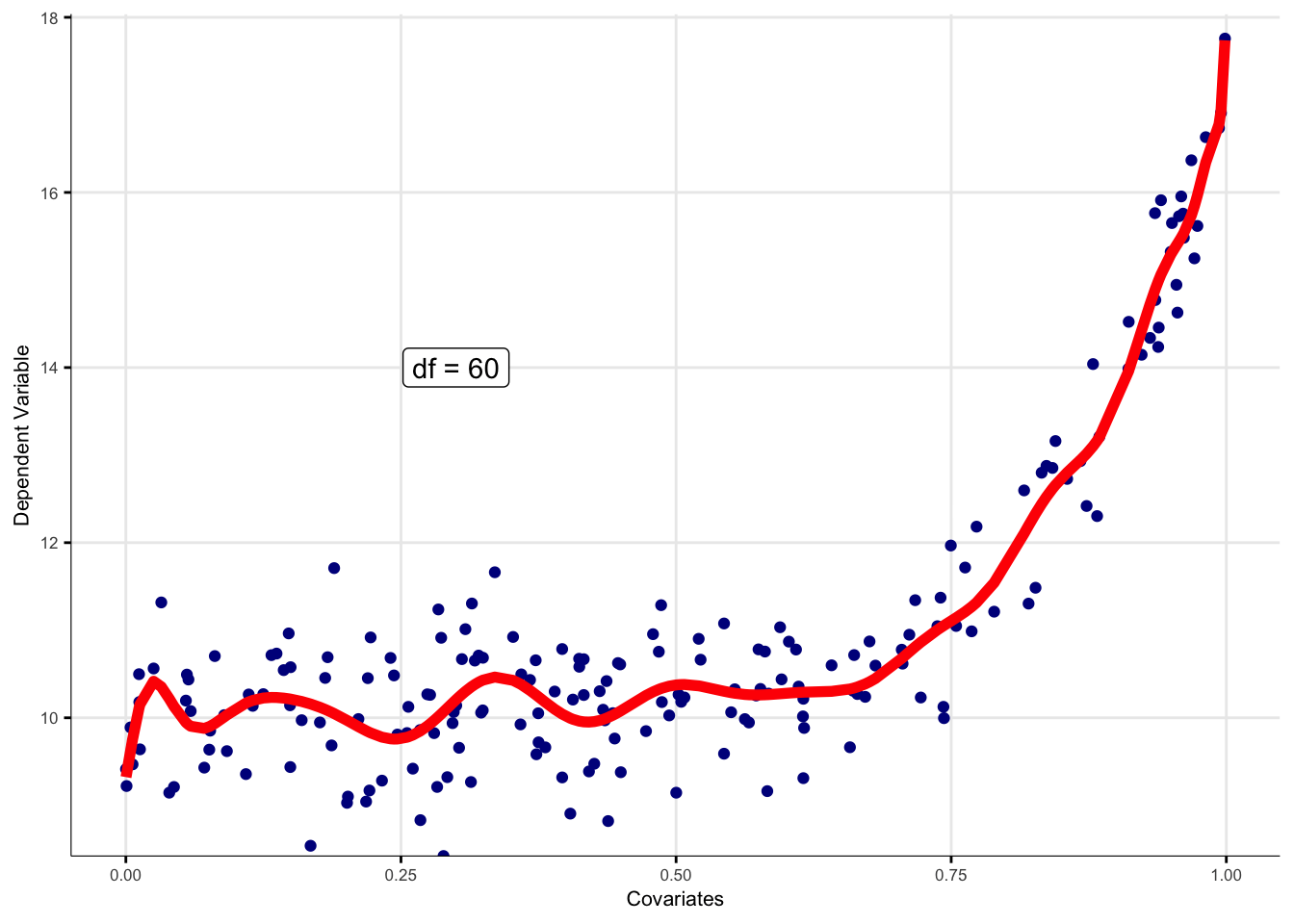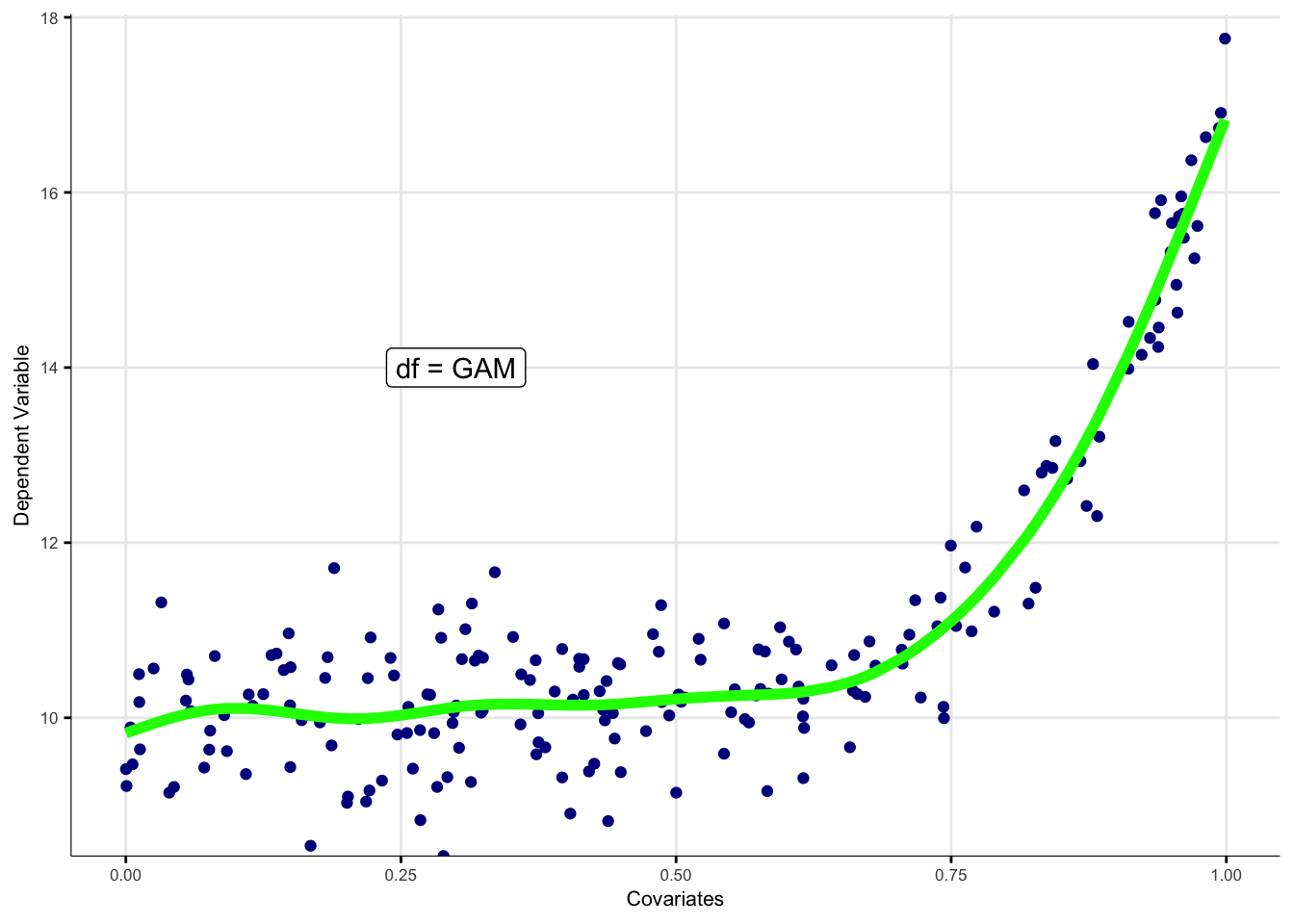
est fixée à 0, alors la transformation appliquée est la moyenne des observations.
Nous illustrons le principe général de la transformation de variable avec le cas suivant.