République
Française

Documentation Datafoncier
Toutes les ressources sur les données foncières
République
Française
Documentation Datafoncier
Toutes les ressources sur les données foncières
Définitions, précisions méthodologiques, limites et précautions d'interprétation
En France comme en Europe, des objectifs convergents de réduction de l'artificialisation ont été intégrés dans les politiques publiques. Ainsi, l'Union Européenne a pour objectif de « supprimer d'ici à 2050 toute augmentation nette de la surface de terres occupée ». En parallèle, la France a publié le 4 juillet 2018 le Plan National Biodiversité, qui vise à atteindre le « Zéro artificialisation nette » (ZAN).
Ce plan contient, dans son action 7, l'engagement de « [publier], tous les ans, un état des lieux de la consommation d'espaces et [mettre] à la disposition des territoires et des citoyens des données transparentes et comparables à toutes les échelles territoriales ». Dans ce contexte, le ministère de la transition écologique a missionné le Cerema, l'IGN et l'INRAe pour produire ces données, qui ont été mises à disposition du public en juillet 2019 sur le portail national de l'artificialisation des sols.
La loi n° 2021-1104 du 22 août 2021 portant lutte contre le dérèglement climatique et renforcement de la résilience face à ses effets (dite loi « Climat Résilience ») a fixé l'objectif d'atteindre le « zéro artificialisation nette des sols » en 2050, avec un objectif intermédiaire de réduction de moitié de la consommation d'espaces naturels, agricoles et forestiers sur la période 2021-2031 par rapport à la décennie précédente.
Le dispositif de mesure national de l'artificialisation se déroule ainsi en deux temps.
Pour la période 2021-2031, on raisonne en consommation d'espaces. La consommation d'espaces naturels, agricoles et forestiers (ENAF) est entendue comme « la création ou l'extension effective d'espaces urbanisés sur le territoire concerné » (article 194 de la loi Climat et résilience). Au niveau national, elle est mesurée par les Fichiers fonciers. Le présent rapport décrit la méthodologie technique de production de ces données.
À partir de 2031, on raisonne en artificialisation nette. L'artificialisation nette est définie comme « le solde de l'artificialisation et de la renaturation des sols constatées sur un périmètre et sur une période donnés. » (article L.101-2-1 du code de l'urbanisme). Au niveau national, elle est mesurée par l'occupation des sols à grande échelle (OCS GE), en cours d'élaboration, dont la production sera engagée sur l'ensemble du territoire national d'ici fin 2024.
La mesure de la consommation d'espaces à partir des Fichiers fonciers est diffusée sur le portail national de l'artificialisation (https://artificialisation.developpement-durable.gouv.fr). Outre cette méthodologie technique, destinée aux techniciens et chercheurs expérimentés souhaitant connaître très précisément la méthodologie utilisée, plusieurs ressources sont disponibles :
La lecture du rapport sur les définitions est un préalable indispensable à la bonne compréhension de la démarche méthodologique.
Ce rapport explicite le processus de création d'indicateurs de consommation d'espaces à partir des Fichiers fonciers en en détaillant les limites d'utilisation et les partis pris issus du traitement. Attention, ce rapport ne traite pas des limites inhérentes à la donnée de base.
Il est admis, en préalable, que le lecteur est au fait de la base de données « Fichiers fonciers », de sa structure, ainsi que des principaux avantages et limites de la base. Si ce n'est pas le cas, il est conseillé de lire le premier rapport traitant de la source de données1 et/ou de consulter le site internet consacré aux données foncières2. Ce rapport est ainsi destiné à un public de techniciens désireux de connaître la manière dont a été constituée la donnée. Il a donc été fait ici le choix de présenter de la manière la plus exhaustive possible les traitements réalisés.
L'exercice mené ici permet d'obtenir des données comparables à toutes les échelles de territoire. Il s'agit de données socles permettant aux territoires de se saisir de ces chiffres. L'apport de cette étude est donc de répondre à la question du « combien ».
Cependant, il s'agit ici d'une méthode nationale. Des méthodes d'observation locales complémentaires seront parfois mieux adaptées pour répondre aux spécificités des territoires.
En outre, il faut rappeler que le nombre d'hectares consommés n'est ici qu'une partie du problème. S'il s'agit d'atteindre le zéro artificialisation nette, il est nécessaire de se pencher sur les causes de cette consommation, et sur les leviers permettant de la réduire. En cela, des analyses nationales et locales plus poussées, notamment dans le cadre d'observatoires fonciers déjà constitués seront nécessaires pour comprendre le « pourquoi ».
Ce rapport retrace le processus de traitement des données Fichiers fonciers. Étape par étape, il sera fait le suivi de la transformation de la donnée de base en des chiffres communaux. De manière condensée, la méthode est la suivante.
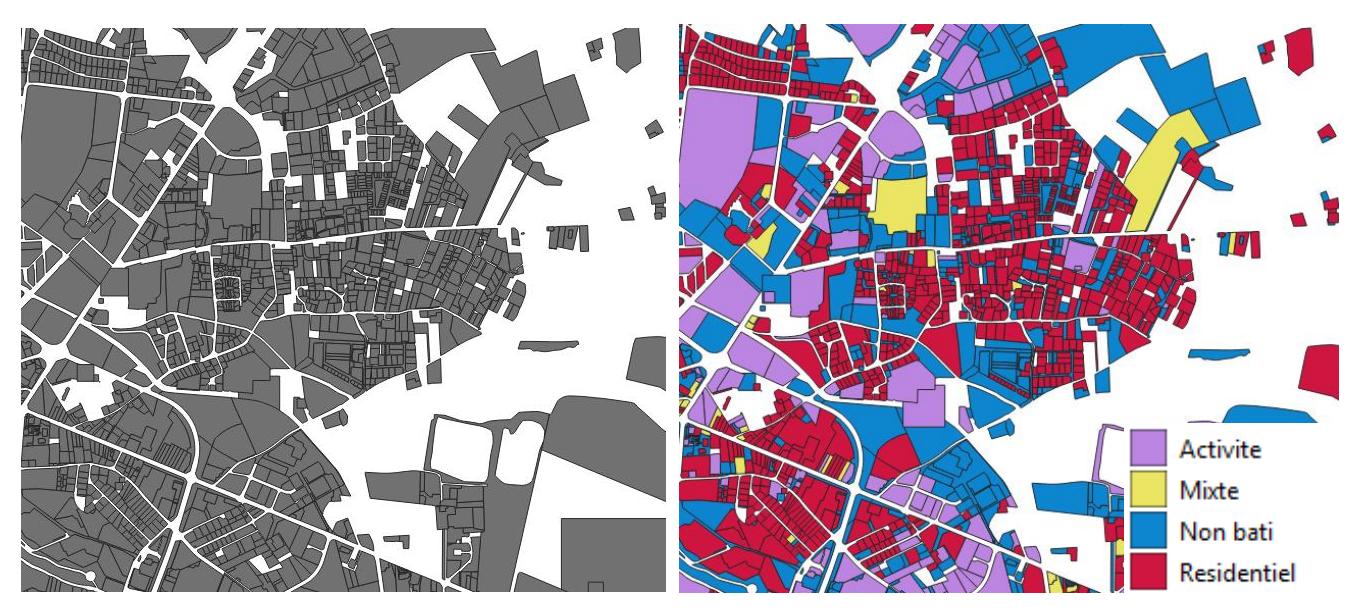
1 – Dans un premier temps, pour tous les millésimes, on classe chaque parcelle des Fichiers fonciers, selon son caractère urbanisé ou non. Ensuite, si elle est urbanisée, il sera précisé son usage (habitat, activité ou mixte).
2 – Une fois cette action réalisée, l'objectif est d'arriver à créer un historique des parcelles. En d'autres termes, il faut arriver à suivre, sur l'intégralité des millésimes, ce que deviennent les parcelles. Ainsi, si une parcelle A se divise, nous devons pouvoir suivre chacune de ses parties, et savoir que ces parties sont issues de A. Dans ce cadre, nous allons travailler à l'îlot, c'est-à-dire un agrégat de parcelle(s) stable sur l'intégralité des millésimes.
3 – À partir de ces deux éléments, nous disposons d'une donnée contenant la filiation des parcelles ainsi que leur usage. À partir de ces éléments, il est possible de calculer les flux de consommation d'espaces.
L'illustration 1 retrace précisément ce processus.
Il s'agit donc de travailler à une maille fine (parcelle ou ensemble de parcelles), en mobilisant des techniques de calcul statistique, et éventuellement quelques méthodes géomatiques. Dans un deuxième temps, les données sont agrégées à une maille communale.
Les données sont travaillées en ne considérant que sur les entités ayant évolué. Il ne s'agit donc pas ici de travailler en stock (« 1 000 ha de cette commune sont urbanisés en 2017 »), mais bien en flux (« 10 ha de cette commune ont été nouvellement urbanisés (= consommés) entre 2016 et 2017 »).
La méthodologie utilisée est ici nouvelle, et remplace les précédents chiffres et données issus des Fichiers fonciers. Il s'agit ici d'une méthodologie plus fine, travaillant à une maille plus resserrée (l'îlot / parcelle et non la commune).
Outre des données plus fines, capables de différencier habitat et activité, il s'agit aussi d'une méthodologie permettant des développements ultérieurs (croisement avec d'autres bases de données exogènes), ce qui améliorera la connaissance du phénomène.
Il est à noter que d'autres méthodes peuvent exister, notamment basées sur l'utilisation des dates de construction des Fichiers fonciers. Pour en savoir plus sur les utilisations possibles et différences de ces méthodes, vous pouvez consulter l'étude sur la consommation d'espaces induite par le logement social3, qui traite entre autres de cette différence.
Les données de consommation d'espaces sont produites depuis 2019 sur l'ensemble des millésimes disponibles. À ce jour, 5 millésimes des données ont été produites.
Suite aux retours terrains, le Cerema a affiné sa méthodologie de production des données. Dans ce contexte, chaque année, la production vient remplacer les données antérieures sur toute la période. Ainsi, les données 2009-20AA sont recalculées sur toute la période, et remplacent intégralement les données de la période précédente.
Ce présent rapport est une mise à jour du premier rapport produit en juin 2019. Il intègre ainsi une partie des réponses des utilisateurs sur la méthodologie, clarifie certains points, et surtout modifie la méthodologie sur les points ayant évolué.
Cette présente méthodologie a pour objectif de créer des données de consommation d'espaces annuelles à une échelle communale. Les données sont aussi séparées selon leurs usages. En d'autres termes, les données sont structurées selon un tableau avec 1 ligne = 1 commune.
Pour chaque année (2011-2012 correspond à la période entre le 1er janvier 2011 et le 1er janvier 2012), on dispose donc :
La méthode de traitement à partir des Fichiers fonciers traite de l'évolution de la consommation d'espaces au niveau national.
La notion d'artificialisation est définie, dans la loi « Climat et résilience », comme « l'altération durable de tout ou partie des fonctions écologiques d'un sol, en particulier de ses fonctions biologiques, hydriques et climatiques, ainsi que de son potentiel agronomique par son occupation ou son usage »4. Cette définition a depuis été complétée par un décret ciblant quels types de sols sont ou non artificialisés.
La loi Climat et Résilience définit la consommation d'espaces comme « la création ou l'extension effective d'espaces urbanisés sur le territoire concerné ». Il s'agit donc de la conversion d'espaces naturels, agricoles ou forestiers en espaces urbanisés.
Dans le rapport, nous utiliserons les termes « NAF » (naturel, agricole ou forestier) et « urbanisés » pour parler des espaces en « stock » : ce terrain est actuellement urbanisé. À l'inverse, le terme de consommation d'espaces qualifiera le flux, c'est-à-dire la conversion d'un espace NAF en un espace urbanisé.
Le rapport contient la méthode de calcul de la consommation d'espaces. Elle s'appuie sur deux traitements préalables explicités en annexe, à savoir :
Le corps du rapport se concentre sur la transformation de données multi-millésime contenant l'usage de la parcelle. À partir de ces données, il va s'agir de :
L'ensemble de ces traitements est réalisé à travers un algorithme nommé Krainbow, développé dans le cadre de cette étude. Le déroulé de l'algorithme Krainbow est présenté dans l'illustration 2.
Les deux étapes explicitées en annexe nous ont permis d'obtenir des données bi-millésime5 contenant les surfaces liées aux différents usages (activité, habitat, mixte). Pour chaque îlot6, nous aurons donc les informations suivantes pour le millésime N et le millésime N+1 :
La surface urbanisée est elle-même divisée entre les éléments suivants :
| îlot | Surf. parcelle 2011 | Surf. urbanisée 2011 | Surf. NAF 2011 | Surf. Act direct 2011 | Surf. Act extrapolé 2011 | Surf. Habitat 2011 | … | Surf. parcelle 2012 | … |
|---|---|---|---|---|---|---|---|---|---|
| îlot1 | |||||||||
| îlot2 | |||||||||
| îlot3 |
L'usage de la parcelle peut être défini de deux manières. En premier lieu, il s'agit d'une affectation directe, selon les locaux présents sur la parcelle selon les Fichiers fonciers. Si cela n'est pas possible, l'affectation est définie par rapport à celle de ses voisins. Dans ce cadre, l'affectation directe est considérée comme plus fiable que l'affectation extrapolée.
Les traitements précédents ne permettent pas d'affecter la totalité des parcelles. Pour certaines parcelles urbanisées, il est impossible d'en déterminer l'usage, même par extrapolation. Ces parcelles sont donc considérées comme « non affectées ».
Outre cette donnée d'entrée, le traitement s'appuie sur plusieurs données exogènes. La liste de ces données est présentée en annexe.
Dans la suite du rapport, nous allons utiliser deux notions :
L'objectif de ce traitement sera de transformer ces données, à l'îlot, en flux. Ce traitement sera réalisé pour observer deux phénomènes.
Dans un premier temps, les flux entre urbanisé, NAF et non cadastré seront déterminés. Cette première sortie sera nommée « flux de consommation d'espaces ».
Dans un deuxième temps, au sein de l'urbanisé, les flux entre habitat, mixte et activité seront déterminés. Cette deuxième sortie sera nommée « flux d'usage ».
Nous avons donc en entrée :
Il s'agit de définir, en sortie, 6 flux :
Les calculs de consommation d'espaces se heurtent à plusieurs problèmes :
Ces parcelles ont été ciblées pour deux raisons :
En outre, une vérification manuelle a été réalisée sur les parcelles dont la consommation d'espaces dépassait les 10 ha.
Dans un premier temps, les unités foncières sur lesquelles un golf ou un terrain militaire était présent ont été repérées. Il s'agit donc des unités foncières sur lesquelles un point d'intérêt de la BD Topo de type « Golf » ou « Terrain militaire » était présent.
Tous les îlots dans lesquels apparaissent l'une de ces parcelles sont exclus des calculs de consommation d'espaces.
Le traitement s'est appuyé sur la base de données « Carma », créée par la DGALN et mise en œuvre par le BRGM. Cette base recense toutes les carrières à une échelle nationale. Ainsi, les parcelles intersectées par la base Carma sont exclues du calcul.
Les parcelles ont une surface totale, qui se divise en surface urbanisée et non urbanisée. Cependant, pour certaines d'entre elles, des problèmes de données conduisent à avoir une surface totale différente de la somme de ses composantes7.
Tous les îlots dans lesquels apparaissent l'une de ces parcelles sont exclus des calculs de consommation d'espaces.
Les remembrements et rectifications fiscales consistent, pour les services des impôts, à redécouper et transformer les parcelles existantes en d'autres. C'est aussi l'occasion de mieux renseigner les nouvelles parcelles. Dans ce cadre, les mises à jour peuvent provoquer des changements des surfaces urbanisées fiscales sans changement physique du sol. Les opérations de remembrement ont ainsi été exclues du calcul de consommation d'espaces.
Les remembrements concernent souvent un grand nombre de parcelles. Pour les exclure du total, plusieurs filtres ont été réalisés :
En conclusion, le calcul de la consommation d'espaces ne prend pas en compte les golfs, les terrains militaires, les carrières, ou les changements dus aux remembrements.
Une fois ce tri réalisé, il s'agit d'estimer les différences entre les millésimes, sur chacun des postes. Nous souhaitons travailler, entre deux millésimes, à périmètre constant8. Dans ce cadre, les surfaces non cadastrées de l'année N ou de l'année N+1 sont complétées pour que les surfaces totales soient les mêmes entre les deux années.
Cette normalisation permet d'éviter les changements de surface dus à un réarpentage des parcelles.
À partir de ces éléments, nous appliquons l'algorithme Kaver, qui transforme donc les 3 deltas en 6 flux (algorithme en annexe).
Cet algorithme pose l'hypothèse que les flux ne peuvent être contraires. En d'autres termes, s'il existe un transfert entre espace NAF et urbanisé, on postulera que le flux contraire (urbanisé vers NAF) sera nul.
Au sein d'un îlot, on ne constatera qu'un seul sens de modification : on ne pourra donc avoir à la fois une consommation d'espaces et une renaturation du même îlot.
Cette hypothèse est dans les faits assez crédible : chaque îlot est situé dans un espace de projet, et est constitué d'une surface plutôt faible (ordre de grandeur de la parcelle9). Il est très rare de constater deux modifications contraires sur le projet sur une année.
Enfin, l'algorithme pose comme contrainte que l'un des flux restants sera égal à 0. En d'autres termes, on postule l'absence de flux circulaires10.
À ce stade, les données sont les suivantes :
| îlot | Urba N → NAF N+1 | NAF N → Urba N+1 | NC N → NAF N+1 | NAF N → NC N+1 | Urba N → NC N+1 | NC N → Urba N+1 | … |
|---|---|---|---|---|---|---|---|
| îlot1 | |||||||
| îlot2 | |||||||
| îlot3 |
Ces données seront ensuite regroupées à l'échelle du territoire d'étude (par exemple la commune).
Nous disposons donc des flux entre NAF, non cadastré et urbanisé pour chaque îlot. L'étape suivante consiste à observer les évolutions au sein de l'urbanisé entre les usages présents, c'est-à-dire :
L'objectif est ainsi de créer, à partir des données d'entrée, des flux de sortie entre les catégories, c'est-à-dire les données suivantes :
3 flux de « création », constitué de :
6 flux de transferts entre habitat, mixte et activité, composé de :
Sur chaque îlot, nous avons donc, pour chaque année, la consommation d'espaces et les surfaces affectées dans les 4 catégories d'usage (habitat, activité, mixte et « non classé »). Les flux en entrée sont les suivants :
| N° îlot | Conso | Hab 2011 | Act 2011 | Mix 2011 | NC 2011 | Hab 2012 | Act 2012 | Mix 2012 | NC 2012 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 200 | 100 | 100 | 100 | 300 | 100 | |||
| 2 | 600 | 300 | 200 | 100 | |||||
| 3 | 0 | 200 | 200 | ||||||
| 4 | 350 | 50 | 400 | ||||||
| 5 | 0 | 100 | 200 | 600 | 600 | 300 | |||
| 6 | 100 | 300 | 400 | ||||||
| 7 | 200 | 100 | 100 | 200 | 600 |
Illustration 7 : Exemple de surface en entrée. Les cases vides correspondent à des données égales à 0 (non représentées ici pour des questions de clarté).
Il faut toutefois noter que le principe sera de ne pas calculer le changement d'affectation au sein de l'îlot. En d'autres termes, les données d'entrée sont l'évolution globale de la consommation d'espaces, et les évolutions de l'habitat, l'activité et le mixte. Les inconnues de l'équation sont les créations de consommation d'espaces pour l'habitat, l'activité et le mixte.
Dans un premier temps, nous souhaitons limiter au maximum la présence du « non affecté » sur le territoire.
Pour chaque îlot, si au sein d'un millésime, il y a présence de non affecté et d'autres catégories, on affecte le non classé à ces catégories, au prorata du poids de ces catégories (cas 1). Cela se fait à enveloppe constante.
Exemple : l'îlot 5 a 200 m² de mixte, 100 m² d'habitat et 600 m² de non affecté, pour le millésime 2011. On affectera ces 600 m² aux catégories présentes, selon leur poids, c'est-à-dire 400 m² au mixte et 200 m² à l'habitat.
Une fois cette étape réalisée, si un millésime ne possède que du non affecté, et que l'autre millésime dispose d'une consommation d'espaces dans l'une des catégories, ce non classé sera affecté au prorata des catégories de l'autre millésime (cas 2).
Exemple : l'îlot 6 a 300 m² d'habitat en 2011, et 400 m² de non affecté en 2012. Ce non classé de 2012 sera transformé en 400 m² d'habitat.
Ces deux étapes se font dans cet ordre, ce qui permet d'affecter les cas les plus compliqués (îlot 7).
Si après ces deux affectations, on ne dispose que du non affecté dans les deux millésimes (c'est-à-dire que les surfaces d'habitat, d'activité ou de mixte sont égales à 0 dans les deux millésimes), on traite ce cas à part. Dans ce cas, on fait la différence entre ces éléments pour créer un flux de « non affecté ».
| N° îlot | Conso | Hab 2011 | Act 2011 | Mix 2011 | NA 2011 | Hab 2012 | Act 2012 | Mix 2012 | NA 2012 | Observations |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 200 | 100 | 100 | 100 | 300 | 100 | Pas de modif | |||
| 2 | 600 | 300 | 360 | 240 | Cas 1 : non affecté 2012 → Mix et Act | |||||
| 3 | 0 | 200 | 200 | Cas 2 : non affecté 2011 → Habitat 2012 | ||||||
| 4 | 350 | 50 | 400 | Cas 3 : non cadastré dans les 2 millésimes | ||||||
| 5 | 0 | 300 | 600 | 600 | 300 | Cas 1 : 600 m² non affecté 2011 → Hab+Act | ||||
| 6 | 100 | 300 | 400 | Cas 2 : non classé 2012 → 400 m² d'habitat | ||||||
| 7 | 200 | 200 | 200 | 300 | 300 | Cas 1+2 : non affecté 2011 → Hab+Act, puis non affecté 2012 affecté selon répartition 2011 |
Illustration 8 : Exemple de surface après application de Kejaune. Les données en gras ont été modifiées. Les cases vides = données égales à 0.
Une fois ces structures modifiées, il s'agit de déterminer les flux. Au final, nous avons 3 données en entrée :
Nous souhaitons, en sortie, 9 flux : 3 flux de création et 6 flux de transfert entre catégories.
De plus, on étudie la stabilité de l'enveloppe, à savoir si la surface urbanisée de l'année N est égale à la surface urbanisée de l'année N+1.
Pour chaque îlot, nous possédons à la fois la surface directe (c'est-à-dire sur la surface sur laquelle il y avait un local) et la surface extrapolée (surface urbanisée sur laquelle il n'y a pas de local, mais pour laquelle l'affectation a été réalisée par voisinage).
En d'autres termes, on différencie pour ces cas l'affectation directe, plus fiable, de l'affectation extrapolée, moins fiable.
Le traitement est basé sur plusieurs principes :
En dehors de ces cas, on applique l'algorithme Korange, qui répartit :
Le fonctionnement complet de cet algorithme est présenté en annexe.
Le traitement réalisé ne prend en compte, à ce stade, que les usages habitat, activité, mixte et inconnu. L'objectif est ici d'extraire les flux de consommation d'espaces induits par les nouvelles infrastructures routières et ferroviaires.
Les routes et voies ferrées sont issues de la BD Topo V3. Le millésime utilisé est le dernier disponible au moment du traitement : pour les données 2009-2022, la BD Topo 2022 a été utilisée.
Cependant, les données issues de la BD Topo (tables « tronçon de route » et « tronçon de voie ferrée ») sont représentées géomatiquement par des lignes. Il est donc nécessaire de leur appliquer un buffer égal à leur largeur pour les représenter en tant que polygone. Les buffers appliqués sont les suivants :
Les parcelles consommées sont intersectées avec la BD Topo retraitée. On compare ensuite la surface de la parcelle avec celle de l'intersection entre parcelle et route / fer. Les parcelles dont plus de 45 % de la surface est intersectée par une route sont classées en usage routier, et les parcelles à plus de 30 % par une voie ferrée sont classées en « fer ». Si une parcelle répond à ces deux critères (cas très rare), elle sera classée en « route ». Ces seuils, définis empiriquement, permettent de croiser les deux couches géographiques en dépit de leurs différences de topologie et de calage.
L'usage routier ou ferroviaire est donc prépondérant par rapport à l'usage précédent. Ainsi, si une parcelle était classée en « habitat », mais intersecte une route à 80 %, elle sera classée en tant que « route ».
Nous avons donc tous les flux recherchés. Il s'agit, à ce stade, d'éliminer encore quelques cas problématiques et de créer une table de synthèse multi-millésime utilisable par tous.
À ce stade s'achève les travaux en bi-millésimes pour créer une table multi-millésimes.
On transforme ici des tables bi-millésime en table multi-millésime, dont l'unité est l'îlot. Ce processus est décrit dans l'annexe 1.
Il subsiste, à ce stade, de rares cas de « rebond » : un îlot est consommé11 entre 2011 et 2012, puis passe de « urbanisé » à NAF12 entre 2012 et 2013. Il s'agit la plupart du temps de la correction d'erreurs, ou alors de projets abandonnés.
Les cas évoqués sont rares (environ 300 cas par département et par bi-millésimes), et ne correspondent pas à de grandes surfaces.
Il s'agit ainsi plutôt de corrections très locales, permettant d'utiliser ces données à une échelle communale.
On repère ainsi les îlots qui ont fait l'objet de deux flux contraires sur 3 millésimes. Sur ces îlots, le flux NAF vers Urba est corrigé des flux Urba vers NAF des deux millésimes suivants.
Nouveau NAF-Urba (N-N+1) = Ancien NAF-Urba (N-N+1) – Urba-NAF (N+1-N+2) – Urba-NAF (N+2, N+3)
Dans tous les cas, ce flux ne peut être inférieur à 0.
Illustration 9 : Îlots avec rebond avant correction
| îlot | NAF-Urba 2011-12 | Urba-NAF 2011-12 | NAF-Urba 2012-13 | Urba-NAF 2012-13 | NAF-Urba 2013-14 | Urba-NAF 2013-14 |
|---|---|---|---|---|---|---|
| îlot1 | 200 | 0 | 0 | 100 | 0 | 50 |
| îlot2 | 100 | 0 | 0 | 0 | 0 | 100 |
| îlot3 | 100 | 0 | 0 | 0 | 0 | 150 |
Illustration 10 : Îlots avec rebond après correction
| îlot | NAF-Urba 2011-12 | Urba-NAF 2011-12 | NAF-Urba 2012-13 | Urba-NAF 2012-13 | NAF-Urba 2013-14 | Urba-NAF 2013-14 |
|---|---|---|---|---|---|---|
| îlot1 | +50 | 0 | 0 | 0 | 0 | 0 |
| îlot2 | 0 | 0 | 0 | 0 | 0 | 0 |
| îlot3 | 0 | 0 | 0 | 0 | 0 | 0 |
À ce stade, nous regroupons toutes les données à l'échelle de travail (par exemple la commune), pour obtenir des flux à l'échelle communale.
Chaque ligne du tableau correspond à une commune du référentiel INSEE de l'année de production (ex : 2023 pour les données 2009-2022). Il faut cependant noter les différences suivantes :
Les chiffres sont présentés de manière annuelle, sur la période considérée. Cependant, nous ne disposons que des chiffres 2009-2011. Dans ce cadre, dans le document final, les chiffres 2009-2010 et 2010-2011 sont les mêmes : ils sont égaux à la moitié des données calculées sur la période 2009-2011.
Les données finales comportent les flux suivants :
Ces flux sont présentés entre chaque bi-millésime.
Lors de la livraison du produit, des données exogènes ont été ajoutées. Il s'agit à ce stade de données INSEE, à savoir :
En outre, les données fournissent le périmètre des Scots, fournis par la Fédération nationale des Scots.
La structure complète de la table est présentée dans le descriptif des données présent sur l'espace de téléchargement des données.
Nous arrivons, à ce stade, au produit final. Certains flux présentant des limites importantes (cf. infra), ils n'ont pas été livrés dans le produit final. Ainsi, les données en open-data présentent les principaux indicateurs et uniquement les données les plus fiables : il s'agit donc de la même donnée, mais avec un nombre de colonnes moindre.
Les données de flux de NAF vers urbanisé sont fiables, ainsi que les flux de création (création d'habitat, d'activité ou de mixte). Il s'agit bien de la consommation d'espaces au sens fiscal.
À l'inverse, les flux d'espaces urbanisés et NAF sont moins fiables. Si parmi eux on peut reconnaître de la réelle renaturation (passage effectif de l'urbanisé vers le NAF), il s'agit aussi de reconfigurations fiscales, la fiscalité des espaces NAF étant moins forte que celle des espaces urbanisés. À ce titre, le flux Urbanisé vers NAF comporte beaucoup trop d'artefacts (changements fiscaux sans changement réel de l'usage du sol) pour être considérés comme fiables. Le flux urbanisé vers NAF ne peut donc être assimilé à de la renaturation.
Les flux partants ou provenant du non-cadastré sont pour leur part fiables, mais ne recouvrent pas forcément une réalité thématique.
Enfin, les flux entre usages doivent encore être expertisés. En effet, il existe plusieurs cas où des changements théoriques d'usages ne sont en réalité que des redécoupages parcellaires. Des recherches sont en cours pour différencier les changements effectifs (requalification d'habitats en activité), des changements mineurs mais faisant changer le seuil (par exemple la transformation d'un local d'activité en habitat, qui pourrait faire passer l'intégralité de la parcelle en « activité ») ou les changements dus à la méthode.
Dans ce cadre, il est vivement recommandé de n'observer que les flux NAF vers urbanisé, ainsi que leur destination (habitat, activité, mixte, fer, route ou inconnu).
Les traitements décrits dans ce chapitre s'inscrivent dans la continuité de la méthodologie nationale de mesure de la consommation d'espaces à partir des Fichiers Fonciers, dont les principes généraux (algorithmes Krainbow, Kirouge, Kejaune, Korange, Kanbleu) sont exposés dans le rapport de référence d'août 2023. Ils constituent des améliorations ciblées, appliquées en fin de chaîne de production et rétroactivement sur l'ensemble de la série 2011–2025, sans modifier les étapes A à D du calcul de base.
⚠️ Ces traitements modifient les valeurs de consommation sur l'ensemble de la période, y compris les années antérieures déjà publiées. Les données 2011–2025 remplacent intégralement les données 2011–2024 calculées l'année précédente.
Le périmètre temporel de la loi Climat et Résilience définit la décennie 2011–2021 comme période de référence pour les objectifs ZAN. Certaines consommations détectées dans les Fichiers Fonciers portent pourtant sur des bâtis antérieurs à 2011 : il s'agit de rattrapages fiscaux, c'est-à-dire de déclarations tardives de constructions déjà réalisées avant 2011 mais non encore enregistrées dans les données fiscales à la date de leur construction. Leur présence biaise la mesure des dynamiques d'artificialisation post-2011, qui constituent l'unique périmètre d'évaluation réglementaire.
Le traitement repose sur l'algorithme dit « jannat », qui exploite le champ jannatmin des Fichiers Fonciers. Ce champ enregistre l'année minimale de construction des bâtiments déclarés sur les parcelles d'un îlot. Pour chaque paire de millésimes (n0, n1), l'algorithme identifie les îlots vérifiant simultanément trois conditions :
jannatmin = −1, code conventionnel du FF pour « absence de bâti »).jannatmin) est antérieure à l'année de début de la période de détection (n0).Lorsque l'année de construction est strictement antérieure à 2009, l'îlot est marqué pour suppression. Les îlots dont l'année de construction est 2009 ou 2010 sont réattribués à la période fictive 2009–2011, puis éliminés lors du filtrage final : seules les consommations avec n0 ≥ 2011 sont conservées dans les tables de diffusion.
Illustration 1 : Logique de décision pour la neutralisation des consommations antérieures à 2011.
Fiabilité de la source. Le champ jannatmin dépend des déclarations des propriétaires et peut être absent, erroné, ou correspondre à une date de permis de construire plutôt qu'à une date de construction effective. Une année de construction mal renseignée peut conduire à une neutralisation incorrecte ou à l'absence de neutralisation d'un vrai rattrapage.
Périmètre de détection restreint. L'algorithme ne s'applique qu'aux îlots pour lesquels aucun bâtiment n'est déclaré en n0. Les cas où le bâtiment existait déjà dans les FF en n0 mais n'avait pas encore modifié le statut fiscal NAF de la parcelle ne sont pas couverts.
Traitement des cas limites 2009–2010. Les îlots dont jannatmin vaut 2009 ou 2010 correspondent à des constructions formellement antérieures à 2011 mais proches de la frontière réglementaire. Leur traitement par réattribution puis filtrage, plutôt que par suppression directe, garantit la cohérence de la série sans introduire d'ambiguïté sur leur statut.
La comparaison millésimée des Fichiers Fonciers attribue toute consommation au premier millésime où la transformation fiscale est enregistrée. Or, un propriétaire peut déclarer tardivement l'achèvement de travaux effectués plusieurs années auparavant - phénomène de rattrapage fiscal. Cette distorsion temporelle concentre artificiellement de la consommation sur certains millésimes, notamment ceux suivant des campagnes de régularisation cadastrale ou des contrôles fiscaux. Le champ jannatmin du Fichier Foncier, qui enregistre l'année de construction déclarée, permet de corriger cette distorsion lorsque la date réelle de construction, postérieure à 2010, est antérieure à l'année de détection.
Le redressement s'appuie sur le même algorithme « jannat » que la neutralisation décrite en 3.1, mais pour les cas où l'année de construction (jannatmin) est ≥ 2011 et strictement inférieure à l'année de début de la période de détection (n0). Dans cette situation, les champs n0 et n1 de l'îlot sont mis à jour pour refléter l'année réelle de construction, déplaçant ainsi la consommation vers le bon intervalle temporel.
Ainsi, un îlot détecté lors de la comparaison 2022–2023, mais dont le bâtiment a été construit en 2018 selon le champ jannatmin, est réattribué à la période 2018–2019. Le cumul des surfaces consommées sur la période 2011–2025 est rigoureusement identique avant et après redressement : seule la répartition annuelle est corrigée.
Chaque réattribution est tracée via l'attribut detail de l'îlot, permettant d'identifier les consommations redressées dans les tables de diffusion et de les soumettre automatiquement au contrôle manuel (voir §3.6).
Illustration 2 : Logique de redressement temporel par l'année de construction.
La dernière année d'observation (ici 2024–2025) ne peut pas bénéficier de reports provenant des années suivantes, car celles-ci ne sont pas encore disponibles. La consommation de cette année est donc systématiquement sous-estimée lors de la publication, et se stabilise progressivement sur les 2 à 3 millésimes suivants, à mesure que les rattrapages fiscaux sont intégrés.
Les chiffres de la dernière année ne doivent pas être utilisés pour des comparaisons strictes avec les années précédentes. Il convient d'attendre la consolidation des millésimes suivants avant d'interpréter cette année isolément.
Certaines surfaces font l'objet d'une consommation détectée dans les Fichiers Fonciers alors qu'elles sont simultanément déclarées comme cultivées dans le Registre Parcellaire Graphique (RPG), qui recense annuellement les surfaces agricoles déclarées à la PAC. Cette coexistence traduit une anticipation de la consommation : le propriétaire a déclaré fiscalement son terrain comme urbanisé avant que la transformation effective du sol ait eu lieu. Ce cas est notamment fréquent dans les ZAC dont la maîtrise foncière est acquise plusieurs années avant l'urbanisation effective.
Le traitement s'effectue par intersection spatiale entre les îlots identifiés comme consommés et les périmètres déclarés au RPG de l'année correspondante. Pour chaque îlot consommé en année n0, l'algorithme interroge successivement les millésimes RPG disponibles depuis n0 jusqu'au dernier millésime RPG disponible, afin de déterminer la première année où l'îlot n'est plus couvert par une déclaration PAC. Trois cas sont distingués :
Illustration 3 : Logique de traitement des intersections avec le Registre Parcellaire Graphique.
Lorsqu'un îlot est exclu temporairement (recouvrement total), il est réintégré à la première année où son contour n'est plus couvert par une déclaration RPG. Lorsque l'îlot est encore couvert au dernier millésime RPG disponible, il est retiré de la série jusqu'à ce qu'un millésime ultérieur confirme sa sortie du RPG. Le cumul de la consommation sur la période 2011–2025 est donc identique avant et après traitement : seule la date d'enregistrement est modifiée.
Pour l'année 2018 à titre d'exemple, l'analyse révèle que plusieurs centaines d'hectares répartis sur plusieurs milliers d'îlots intersectaient totalement le RPG. Parmi ces îlots, environ 80 % ont fait l'objet d'une réattribution vers une année ultérieure de consommation effective. Ce traitement s'avère particulièrement utile pour retracer les opérations d'aménagement progressives (ZAC notamment), où la déclaration fiscale intervient souvent à l'ouverture de l'opération alors que la consommation effective est étalée sur plusieurs années.
L'article 184 de la loi Climat et Résilience, précisé par le décret n°2023-1408 du 29 décembre 2023, exempte du décompte de la consommation d'espaces les installations photovoltaïques au sol et agrivoltaïques répondant à des critères techniques précis. Ces installations, bien que détectées comme consommation dans les Fichiers Fonciers par changement du statut fiscal de la parcelle, doivent être exclues de la mesure nationale.
Le traitement repose sur une intersection géométrique entre les îlots identifiés comme consommés et les périmètres des installations susceptibles d'exemption, issus des données IGN et des déclarations des porteurs de projets. Deux millésimes de données PV sont mobilisés et consolidés : les installations référencées sur la période 2017–2020 et celles référencées sur la période 2021–2023. En cas de doublon, le premier référencement est retenu.
Pour chaque îlot consommé, l'algorithme teste l'intersection spatiale avec les périmètres PV. Lorsqu'une intersection est détectée, les attributs de l'installation (caractère agrivoltaïque, flottant, présence d'une date d'exemption ou d'une justification technique) sont examinés. L'îlot est exclu de la consommation si au moins une des conditions d'exemption est vérifiée. Cette approche spatiale s'affranchit de la temporalité des consommations : elle s'applique indépendamment de l'année de détection fiscale, évitant ainsi les biais d'anticipation ou de rattrapage propres à la source Fichiers Fonciers.
Lorsqu'un îlot consommé intersecte un parc photovoltaïque déclaré, la surface d'intersection est déduite de la consommation comptabilisée. Chaque îlot neutralisé reçoit un attribut de traçabilité dans les données parcellaires.
Sur la période 2011–2022, le traitement neutralise environ 300 ha de consommations cumulées, avec un pic constaté en 2021, témoignant de l'accélération du déploiement photovoltaïque sur cette période. Ces volumes restent modestes à l'échelle nationale mais peuvent être significatifs localement, notamment dans les zones à forte concentration de projets agrivoltaïques.
La méthode de détection par comparaison de millésimes Fichiers Fonciers génère un grand nombre d'îlots de très faible surface. Ces micro-consommations posent plusieurs problèmes :
Le seuil de suppression retenu est de 50 m², correspondant à l'UMI du bâti dans l'OCS GE. Ce seuil assure la cohérence entre la mesure par Fichiers Fonciers et la mesure par télédétection, tout en éliminant les consommations dépourvues d'enjeux territoriaux significatifs.
Ce seuil ne s'applique qu'aux îlots isolés. Les îlots de surface inférieure à 50 m² appartenant à un ensemble spatial de consommations contenant au moins un îlot supérieur à 5 ha sont maintenus dans la chaîne de traitement. Cette exception préserve la cohérence géographique des grandes opérations d'aménagement, dont certains îlots périphériques de faible surface font partie intégrante.
Les catégories de taille 0–5 m², 5–20 m² et 20–50 m² représentent, sur la période 2011–2025, une part importante du nombre total d'objets géographiques produits par la chaîne de détection. À titre d'illustration, les îlots supprimés constituent typiquement plus de la moitié des enregistrements en entrée de la table finale, pour un poids surfacique cumulé inférieur à 2 % de la consommation totale nationale. Cette répartition illustre un paradoxe caractéristique : les micro-consommations constituent un volume important d'objets géographiques, mais leur poids surfacique est négligeable. La suppression améliore significativement les performances de diffusion des fichiers parcellaires - en taille, en temps de rendu cartographique et en lisibilité - sans affecter matériellement les statistiques communales ou départementales.
Dans les millésimes précédents, le contrôle manuel par analyse de photographies aériennes portait sur les îlots isolés présentant une consommation supérieure à 10 ha. Le taux de correction constaté était d'environ 10 % des surfaces vérifiées.
À compter du millésime 2025, le seuil de déclenchement du contrôle manuel est abaissé de 10 ha à 5 ha. L'abaissement du seuil est rendu possible par l'amélioration des outils de production et d'analyse visuelle, qui permettent de traiter un volume accru de dossiers dans des délais compatibles avec le calendrier de publication. Il est également justifié par le constat que la classe des consommations comprises entre 5 et 10 ha concentre une part non négligeable d'erreurs de détection, notamment pour les opérations d'aménagement à maîtrise foncière précoce et les grandes emprises agricoles converties.
Le contrôle porte désormais sur les ensembles de consommations et non plus sur les seuls îlots isolés. Cette évolution repose sur un algorithme de clustering spatial (DBSCAN) appliqué à l'ensemble des îlots consommés, département par département et commune par commune.
Le clustering regroupe les îlots géographiquement proches en clusters cohérents. Un cluster est signalé pour contrôle dès lors qu'il contient au moins un îlot dont la surface consommée dépasse le seuil de 5 ha. L'ensemble du cluster - y compris les îlots de surface inférieure au seuil - est alors soumis à la revue manuelle par photographies aériennes. Ce mécanisme remplit deux fonctions :
Par ailleurs, les îlots faisant l'objet d'un redressement temporel (§3.2), d'une divergence avec le millésime précédent, ou d'un indice de confirmation insuffisant (calculé à partir de l'évolution parcellaire, bâtimentaire, de propriété et des autorisations SITADEL) sont également soumis au contrôle manuel, indépendamment de leur surface.
L'indice de confirmation est un score composite calculé pour chaque îlot consommé, visant à évaluer la robustesse de la détection à partir de sources d'information partiellement indépendantes des Fichiers Fonciers. Un indice faible signifie que la consommation repose uniquement sur la comparaison fiscale, sans corroboration extérieure, et justifie un examen manuel. Il est diffusé dans les tables parcellaires, permettant aux utilisateurs d'évaluer la qualité individuelle de chaque enregistrement.
1. Évolution parcellaire (qual_evolpar) compare la composition en parcelles de l'îlot entre n0 et n1 en s'appuyant sur les listes d'identifiants parcellaires (l_idparn0, l_idparn1). Une restructuration du découpage cadastral (fusion ou division de parcelles) est caractéristique d'une opération foncière intentionnelle et constitue un signal positif. Une simple modification d'identifiant sans changement de structure n'apporte pas de signal.
| Modalité | Interprétation | Score |
|---|---|---|
identique |
Mêmes parcelles en n0 et n1 | 0 |
modif_idpar |
Identifiants modifiés, structure inchangée | 0 |
fusion |
Moins de parcelles en n1 qu'en n0 | 4 |
division |
Plus de parcelles en n1 qu'en n0 | 4 |
2. Apparition de bâtiments (qual_difnbat) compare le nombre de bâtiments déclarés (nbat) sur les parcelles de l'îlot entre n0 et n1 par jointure spatiale avec les tables parcellaires des Fichiers Fonciers. Seuls les îlots présentant un gain net de bâtiments sont concernés ; les autres reçoivent un score nul. C'est l'indicateur au poids le plus élevé dans l'indice, car il signale directement une occupation physique du sol.
| Modalité | Interprétation | Score |
|---|---|---|
| Aucun gain de bâtiments | nbat(n1) − nbat(n0) ≤ 0 |
0 |
ajout bat |
Gain de bâtiments sur des parcelles déjà bâties en n0 | 5 |
apparition bat |
Apparition de bâtiments sur des parcelles sans bâti en n0 | 5 |
3. Changement de propriétaire (qual_evol_idprocpte) compare les ensembles d'identifiants de compte de propriété (idprocpte) entre n0 et n1. Une mutation foncière accompagne fréquemment les opérations d'urbanisation, mais ce signal reste peu discriminant pris isolément ; son poids dans l'indice est donc limité.
| Modalité | Interprétation | Score |
|---|---|---|
meme_idprocpte |
Mêmes propriétaires en n0 et n1 | 0 |
idprocpte_null |
Données propriétaire absentes sur l'un des deux millésimes | 0 |
diff_idprocpte |
Au moins un propriétaire différent entre n0 et n1 | 1 |
4. Autorisation d'urbanisme SITADEL (qual_sitadel) croise spatialement l'îlot avec la base nationale des autorisations d'urbanisme géolocalisées (permis de construire, déclarations préalables). Lorsqu'une intersection spatiale est trouvée, l'autorisation temporellement la plus proche de l'année de détection est retenue. La présence d'une autorisation constitue un signal de confirmation solide, indépendant des Fichiers Fonciers.
| Modalité | Interprétation | Score |
|---|---|---|
pas d autorisation |
Aucune autorisation spatialmente intersectante | 0 |
présence autorisation |
Au moins une autorisation intersectante détectée | 3 |
L'indice est calculé par normalisation de la somme des quatre scores sur une plage [50 ; 99] :
Indice = 50 + 49 × (somme des scores / 13)
Le dénominateur 13 est le score maximal théorique (4 + 5 + 1 + 3). L'indice vaut 50 en l'absence de tout signal de corroboration - plancher reflétant le fait qu'une consommation détectée par les FF présente déjà par construction une probabilité non nulle d'être réelle - et 99 lorsque tous les signaux sont présents simultanément.
Chaque correction issue du contrôle manuel est documentée et tracée dans la chaîne de production. Pour les données diffusées à l'échelle parcellaire, les îlots ayant fait l'objet d'une correction manuelle conservent un attribut spécifique facilitant les contrôles qualité a posteriori par les utilisateurs ayants-droits.
Les six traitements s'appliquent en séquence, après les étapes A à D du calcul de base. L'ordre n'est pas arbitraire : le redressement par l'année de construction (étape 2) est appliqué avant le redressement RPG (étape 3) car il peut neutraliser certains îlots antérieurs à 2011 qui n'ont alors pas à être examinés par le traitement RPG. La neutralisation photovoltaïque (étape 4) intervient après tous les redressements temporels, ce qui garantit qu'elle s'applique à l'année de consommation effective et non à l'année de déclaration fiscale.
Illustration 4 : Séquence d'application des nouveaux traitements en fin de chaîne de production.
Les étapes ① et ② partagent le même algorithme de détection (algorithme « jannat ») et sont réalisées conjointement dans un même modèle dbt, avant que le filtre de taille ⑤ ne soit appliqué. Les îlots appartenant à un cluster de grande consommation (voir §3.6.3) sont exemptés du filtre ⑤ afin de préserver la cohérence géographique des ensembles d'aménagement soumis au contrôle manuel ⑥.
L'objectif de cette étude est de constituer une base de données reprenant toutes les informations entre les parcelles ainsi que leur devenir. Le présent rapport retrace la méthode qui permettrait de créer une table multi-millésimes.
Cette présente étude vient à la suite d'une première étude réalisée en 2016 et disponible ici : https://datafoncier.cerema.fr/etude-multi-millesimes
Elle constitue un préalable indispensable à la bonne compréhension de la base actuelle et de ses retraitements. En particulier, il est nécessaire d'en (re)lire la partie relative aux parcelles.
La parcelle cadastrale est définie comme « une portion de terrain d'un seul tenant appartenant à un même propriétaire, située dans une même commune, une même section et un même lieu-dit »13.
L'ensemble des parcelles constitue le plan cadastral.
La parcelle est constituée :
Enfin, une parcelle possède un identifiant, codé sur 14 caractères14, composé :
Par exemple, la parcelle 59 001 000 AA 0022 :
L'évolution d'une commune est globalement de deux ordres :
Dans le cadre d'une évolution de commune de type fusion, l'identifiant cadastral comporte à la fois le nouveau code INSEE et un suffixe de 3 chiffres reprenant l'ancien code INSEE de la commune fusionnée. Pour les communes rétablies (anciennement fusionnées), c'est ce suffixe qui devient les trois derniers chiffres du code INSEE de la commune rétablie. Autrement dit, par une comparaison multi-millésimes, il est possible de suivre une parcelle dans le temps, même avec un changement de commune. De plus, il est possible de dire si un identifiant de parcelle est modifié à cause d'une fusion ou d'un rétablissement de commune.
Par exemple, la parcelle 59 001 000 AA 0022 existe en 2012. En 2013, la commune 59 001 est absorbée par la commune 59002. La parcelle deviendra donc 59002 001 AA 0022.
Les remembrements et modifications fiscales sont une opération de restructuration du sol ayant pour objet de remodeler le parcellaire existant. Dans ce cadre, il s'agit d'une opération transformant de nombreuses parcelles en de nombreuses autres. Il n'existe pas de relations directes entre les parcelles, et les données attributaires (surfaces…) sont revues.
Nous traiterons ainsi des deux bases de données :
Il s'agira donc à la fois d'un stock au 1er janvier pour les FF, et d'un flux de transformation pour les DFI. Pour faciliter la compréhension, les DFI seront présentés sous forme de flèches pleines, et les parcelles sous forme de rectangles.
Les Fichiers fonciers contiennent l'information sur les parcelles et leur état au 1er janvier de l'année du millésime. Ainsi, le millésime 2012 contiendra les parcelles présentes au 1er janvier 2012.
Outre le numéro de parcelle, les Fichiers fonciers contiennent toute l'information attributaire liée aux parcelles (usage, propriété…). Ces informations permettront des usages divers de la base multi-millésimes, et notamment l'évaluation de la consommation d'espaces.
Les DFI sont une base de données reprenant l'historique des parcelles. Ce fichier est présent en open data sur data.gouv.fr15, mis à disposition par la DGFiP depuis janvier 2018.
Le fichier contient donc, pour chaque département, l'historique des opérations qu'ont subi les parcelles depuis 1990 (hors modifications communales ou remembrements).
Les DFI sont retraités par le Cerema, afin d'obtenir une base de données contenant les colonnes suivantes :
Chaque ligne contient un couple parcelle-mère / parcelle-fille. Un identifiant de DFI peut donc être présent sur plusieurs lignes. Par exemple, si la parcelle A se divise en 3 parcelles B, C et D, nous aurons les données présentées dans le tableau ci-dessous. Il s'agit donc du tableau représentatif d'un graphe.
Par la suite, l'opération de transformation liée à un unique identifiant DFI sera nommée « filiation ».
| id_dfi | Parcelle_mère | Parcelle_fille | Date | Type |
|---|---|---|---|---|
| 590010001 | A | B | 01/04/12 | division |
| 590010001 | A | C | 01/04/12 | division |
| 590010001 | A | D | 01/04/12 | division |
Illustration 13 : Exemple de filiation
Les DFI contiennent les transformations suivantes :
Chaque transformation est exclusive des autres. En d'autres termes, si une parcelle A est créée à partir d'une parcelle B et de non cadastré, nous aurons la présence de deux transformations (Non cadastré vers X et réunion de X et B pour créer A).
Lorsque deux communes fusionnent, les numéros de parcelles de la commune absorbée modifient leurs 8 premiers caractères. Ainsi, si deux communes fusionnent le 1er juin 2013, on trouvera :
À l'inverse, les DFI sont mis à jour continuellement avec les fusions de communes, et ce même si les évolutions de parcelles ont lieu antérieurement à la fusion. Si la parcelle est issue d'une évolution ayant eu lieu en 2009 (soit avant la fusion de commune) : elle sera répertoriée dans les DFI en tenant compte de la fusion de commune.
On aura alors une évolution du type 59002001AA0030 → 59002001AA0025, et ce même si les parcelles n'avaient pas ce nom au moment de l'évolution.
Le traitement s'opère en plusieurs étapes, de la plus simple à la plus complexe.
Dans un premier temps, la liaison est réalisée entre deux millésimes. Ces bi-millésimes sont ensuite fusionnées pour créer le fichier multi-millésimes.
Pour plus de facilité, nous établirons nos exemples sur le bi-millésime 2013-2014. Le traitement est cependant développé sur tous les bi-millésimes disponibles actuellement, à savoir 2009-2011, 2012-2013, 2013-2014…
Les données sont mises à jour annuellement. À la date d'écriture de ce rapport (août 2023), le dernier millésime disponible est 2022.
L'objectif du traitement est de réaliser l'appariement entre deux millésimes, c'est-à-dire :
La base de données en sortie aura donc la forme suivante :
| Parcelles N0 | Parcelles N1 | Commentaire |
|---|---|---|
| [A] | [A] | La parcelle A est stable : elle est présente dans les deux millésimes |
| [B] | [C ; D] | La parcelle B était présente sur le millésime N0. Elle s'est transformée en les parcelles C et D, présentes toutes les deux dans le millésime N1 |
| [E ; F ; G] | [H ; I] | Les parcelles E, F et G, présentes dans le millésime N0, se sont transformées en les parcelles H et I, présentes dans le millésime N1 |
| [K] | [Non Cadastré] | La parcelle K, présente dans le millésime N0, est passée en non cadastré |
| [L ; Non cadastré] | [M ; N] | Les parcelles M et N sont issues de la parcelle L et du non cadastré |
Les Fichiers fonciers constituent un stock au 1er janvier du millésime. À l'inverse, les DFI constituent un flux. Le travail consiste donc à faire coïncider les parcelles des Fichiers fonciers avec les DFI16, avec pour objectif de créer les liaisons entre parcelles.
Le traitement sera réalisé par étapes, chacune d'entre elles permettra de mettre en relation des parcelles de l'année N0 avec des parcelles de l'année N1.
Chaque étape classe donc un certain nombre de parcelles. L'étape suivante se concentrera uniquement sur les parcelles n'ayant pas été classées précédemment.
Le traitement revient donc à recréer un arbre, reprenant les liaisons entre les parcelles. On cherchera ensuite à repérer chaque arbre indépendant, c'est-à-dire toutes les parcelles en relations les unes avec les autres.
Un exemple d'arbre indépendant, faisant la liaison entre les parcelles A et B d'un côté et C de l'autre est présenté ci-dessous.
Pour chaque parcelle présente dans les millésimes des Fichiers fonciers, on recrée un nom post-fusion de communes. Par exemple, si une fusion a eu lieu entre la commune 59001 et 59002, on renommera toutes les parcelles commençant par 59001000 en 59002001XXX.
Ce renommage permettra de réaliser les liaisons avec les DFI, qui comportent toujours les numéros de parcelles post-fusions, quelles que soient leurs dates.
La grande majorité des parcelles (99,1%) ne change pas entre deux millésimes. La première étape consiste donc à traiter ces parcelles, pour lesquelles il n'y a pas d'évolution.
Cette étape permet en outre de récupérer la liste des parcelles existantes dans le millésime N0 et absentes de N1 et inversement, qui seront ensuite traitées dans les étapes ultérieures.
On traite ensuite les évolutions simples de parcelles, c'est-à-dire les parcelles dont la totalité des parcelles mères et des parcelles filles est présente dans les deux millésimes.
Il faut ainsi vérifier :
Par définition, le non cadastré ne peut être présent dans les parcelles. On classe ensuite les parcelles :
Dans le 2e cas, il s'agit des parcelles qui apparaissent pour la première fois dans les millésimes.
Il peut potentiellement se passer plusieurs évolutions de DFI entre deux millésimes des Fichiers fonciers. Dans ce cadre, il est nécessaire d'arriver à identifier l'ensemble des parcelles-mères et des parcelles-filles.
Dans l'exemple ci-dessous, les parcelles A et B sont présentes en 2013, et les parcelles D et E en 2014. Elles sont cependant liées par deux filiations qui passent par une parcelle C, qui n'aura pas le temps d'apparaître ni dans le millésime 2013, ni dans le millésime 2014 des Fichiers fonciers.
Il est ainsi nécessaire de repérer les parcelles étant en relation les unes avec les autres. Le travail est ainsi réalisé sur les DFI : on reprend, toutes les filiations comprises entre deux dates déterminées17. Il s'agit ainsi d'une liste des liaisons entre parcelles.
Le détail de cet algorithme est présenté en annexe.
On considère ainsi que les DFI sont liés entre eux à partir du moment où ils possèdent au moins un élément en commun18.
| Parcelle N0 | Parcelle N1 | Identifiant DFI |
|---|---|---|
| A | B | 001 |
| A | C | 001 |
| B | D | 002 |
| B | E | 002 |
| Non Cadastré | F | 003 |
| D | G | 004 |
| F | G | 004 |
| H | J | 005 |
| I | J | 005 |
Illustration 20 : Tableau des filiations (à gauche) et correspondance sous forme de graphe (à droite). Toutes les parcelles se verront attribuer la même « couleur », témoignant de leur appartenance à un même lot.
À ce stade, on ne sait cependant pas si ces parcelles sont présentes ou non dans les Fichiers fonciers.
Une fois que l'on a retracé les liaisons entre les arbres, on regarde les extrémités de chacun d'entre eux, à savoir les parcelles n'ayant pas de parcelle-mères ou pas de parcelles filles. Dans notre exemple précédent, il s'agit des parcelles A, H et I d'un côté, et E, G et J de l'autre.
On regarde ensuite si l'intégralité de ces extrémités sont présentes dans le millésime N0 ou N1 des Fichiers fonciers.
Dans notre exemple précédent, si les extrémités sont présentes, on insérera les lignes suivantes dans notre résultat :
| Parcelle N0 | Parcelle N1 |
|---|---|
| [A ; Non cadastré] | [E ; G] |
| [H ; I] | [J] |
Lorsque les extrémités des arbres ne sont pas présentes dans les millésimes, on réalise un traitement pour « élaguer » les arbres, à savoir couper les branches inutiles.
Dans notre cas précédent, nous ne retrouvons pas la parcelle « G » dans le millésime N1. Cependant, nous retrouvons les parcelles D et F : il faut donc supprimer la dernière liaison (D+F → G).
À ce stade, nous avons traité la majeure partie des parcelles (99,85%). Il nous reste cependant, dans les deux millésimes N et N+1, des parcelles n'ayant pas réussi à s'unir, notamment pour des questions de « sauts de millésime ».
Dans le peu de parcelles restantes, on observe parfois le phénomène suivant. Une parcelle A est présente en 2011, absente en 2012, puis à nouveau présente, sous la même forme, en 2013. Ce phénomène peut se présenter sous diverses variantes :
Il est à noter que les exemples précédents ont été présentés avec un seul saut de millésime. On peut cependant (rarement) retrouver des sauts de plusieurs millésimes (ex : présence en 2011, absence entre 2012 et 2015, et présence en 2016). Ce phénomène reste toutefois très rare.
Lors de notre traitement, nous repérons la parcelle manquante, et nous la reportons artificiellement, avec ses caractéristiques, dans un autre millésime. Il a été fait le choix méthodologique de systématiquement reprendre les caractéristiques de la parcelle figurant dans le millésime suivant.
À ce stade, il reste plusieurs éléments :
Il faut noter que les remembrements concernent la quasi-totalité des parcelles restantes (soit 0,15 %).
Dans l'étape 6, toutes les parcelles restantes de l'année N d'une commune sont mises en relation avec toutes les parcelles restantes de l'année N+1 de cette commune.
Au niveau national, sur l'intégralité des millésimes disponibles lors de la rédaction de ce guide19, cela revient à traiter 1 191 141 923 parcelles, réparties comme suit :
| Étape | Nombre de parcelles traitées | Pourcentage |
|---|---|---|
| Étape 1 (stabilité) | 1 090 308 396 | 99,26 % |
| Étape 2 (lien direct avec les DFI) | 6 321 229 | 0,58 % |
| Étapes 3 et 4 (liaisons complexes) | 298 892 | 0,03 % |
| Étape 5 (sauts de millésimes) | 197 136 | 0,02 % |
| Étape 6 | 1 273 903 | 0,12 % |
Cependant, il est nécessaire de rappeler que les phénomènes que l'on souhaite observer sont situés dans les parcelles qui suivent une évolution. Par exemple, les étapes 3 et 4 sont peu nombreuses par rapport au stock global des parcelles, mais concernent majoritairement des projets d'aménagement, pour lesquels l'observation est importante.
Il est donc nécessaire de pondérer les chiffres présents, en rappelant que les phénomènes intéressants à observer sont situés dans les étapes 2 et ultérieures.
À ce stade, nous avons donc les liaisons entre les tables bi-millésimes. Il s'agit à ce stade de recréer une table unique multi-millésime. L'identifiant de cette table sera nommé idilot. Ces îlots constitueront ainsi un périmètre stable au cours de tous les millésimes.
Lors de l'arrivée d'autres millésimes des Fichiers fonciers, la totalité de ces îlots sera donc recalculée.
La table finale aura ainsi la structure suivante, après ajout des champs thématiques (cf. infra) :
| 2009 | 2011 | 2012 | nblocal 2012 | nblocal 2013 |
|---|---|---|---|---|
| [A] | [A] | [B ; C] | 0 | 0 |
| [F] | [F] | [F] | 2 | 7 |
| [G ; H] | [I ; J ; K] | [I ; J ; K] | 3 | 3 |
À partir des tables bi-millésimes, nous reprenons les liaisons donnant lieu à modification. En d'autres termes, il s'agit des liaisons établies dans les étapes 2 et suivantes.
On transforme ces liaisons en une base de deux colonnes, mettant en lien deux parcelles. Une liaison entre les parcelles [G ; H] et [I ; J ; K] sera ainsi transformée en le tableau suivant :
| Colonne1 | Colonne2 |
|---|---|
| G | I |
| G | J |
| G | K |
| H | I |
| H | K |
| H | J |
Toutes ces liaisons, dans la totalité des bi-millésimes, sont insérées dans ce tableau à deux colonnes.
On réalise sur ce tableau multi-millésime l'algorithme de recherche de graphes connexes (cf. annexe), de la même manière que lors de l'étape 3. Un indicateur, commun à toutes les parcelles qui partagent une liaison, et ce quel que soit le millésime, sera créé.
| Colonne1 | Colonne2 | Bi-millésime concerné | Identifiant du lot |
|---|---|---|---|
| G | I | 2012-2013 | lot1 |
| G | J | 2012-2013 | lot1 |
| G | K | 2012-2013 | lot1 |
| H | I | 2012-2013 | lot1 |
| H | J | 2012-2013 | lot1 |
| H | K | 2012-2013 | lot1 |
| I | L | 2013-2014 | lot1 |
| I | M | 2013-2014 | lot1 |
À partir de cette table, on crée une table de correspondance, qui décrira à quel lot appartient chaque parcelle. En d'autres termes, il s'agira de la table suivante, qui reprend la totalité des parcelles présentes pour la totalité des millésimes :
| idpar | lot |
|---|---|
| G | lot1 |
| H | lot1 |
| I | lot1 |
| J | lot1 |
| K | lot1 |
| L | lot1 |
| M | lot1 |
À partir de la table précédente, on regroupe les tables bi-millésimes selon l'appartenance à ces lots. On réalise une jointure, sur l'identifiant du lot, entre tous ces bi-millésimes pour obtenir la table finale :
| Idlot | 2009 | nblocal 2009 | 2011 | Nblocal 2011 | 2012 | Nblocal 2012 | 2013 | Nblocal 2013 | geometry |
|---|---|---|---|---|---|---|---|---|---|
| lot1 | [A] | 0 | [A] | 0 | [B ; C] | 0 | [D ; E] | 0 | |
| lot2 | [F] | 0 | [F] | 2 | [F] | 2 | [F] | 7 | |
| lot3 | [G ; H] | 0 | [I ; J ; K] | 0 | [I ; J ; K] | 3 | [J ; K ; L ; M] | 3 |
L'îlot est le plus petit périmètre stable au cours de la période considérée. En d'autres termes, ce périmètre global ne change pas : tout au plus ses subdivisions changent. Pour une parcelle sans changement sur toute la période, l'îlot sera égal à la parcelle.
L'îlot est donc un espace de projet. Il s'agit de l'agglomération de parcelles se modifiant. C'est à partir de cet îlot que l'on pourra donc tenter de repérer les projets d'urbanisme, à savoir les lotissements ou zones d'activités.
Il faut toutefois rappeler que le contour de l'îlot est refait chaque année : le l'îlot du multi-millésime 2009–2019 ne sera ainsi pas forcément le même que le l'îlot du multi-millésime 2009–2022.
Ce rapport présente ainsi la méthodologie générale de traitement des fichiers fonciers, base de données d'origine fiscale, afin de mesurer la consommation d'espaces naturels, agricoles et forestiers. Cette méthodologie fait l'objet d'améliorations en continu en fonction des remontées des utilisateurs (collectivités, services de l'État…) et des besoins des politiques publiques.
Les évolutions cadastrales représentent un défi important dans l'exploitation des données. La méthodologie présentée ci-dessus permet ainsi de suivre l'évolution d'un ensemble de parcelles stables tout au long de leur vie. Au cœur d'un même îlot, on peut ainsi observer les compositions / recompositions de parcelles.
À ce titre, il est ainsi possible de suivre, sur chacun de ces îlots, les évolutions physiques telles que présentées dans les Fichiers fonciers. Il est possible de suivre des opérations de construction au sein de ces mêmes îlots.
En parallèle de ce traitement, des champs thématiques présents dans les Fichiers fonciers pourront être inclus. En particulier, il est possible d'inclure des champs relatifs à la consommation des espaces naturels, agricoles et forestiers. Cette méthodologie a été notamment utilisée dans 2 études présentes sur le portail national de la consommation d'espaces :
Notre base de données est constituée de nombreux liens entre parcelles, constitués par les filiations. Nous souhaitons retrouver les îlots, c'est-à-dire étiqueter toutes les parcelles ayant au minimum un lien entre elles.
En théorie des graphes, retrouver les îlots indépendants est équivalent à la recherche des composantes connexes d'un graphe non orienté.
Nos données sont stockées dans une base de données relationnelles, ce qui entraîne un stockage de l'arbre sous forme de liste d'adjacence. Dans l'exemple de l'illustration 20, ce sera donc sous la forme suivante :
| Début | Fin |
|---|---|
| A | B |
| A | C |
| B | D |
| B | E |
| Non Cadastré | F |
| D | G |
| F | G |
| H | J |
| I | J |
Illustration 24 : Exemple de liste d'adjacence
De manière classique, pour rechercher les composantes connexes du graphe, un simple parcours en profondeur du graphe suffit. En d'autres termes, il s'agit de l'algorithme suivant :
S'il existe, dans l'ensemble de la base, des sommets non marqués, reprendre à l'étape 1 et choisir une autre couleur. Sinon, stopper l'algorithme.
flowchart LR
A((A)) --- B((B))
A --- C((C))
B --- D((D))
E((E)) --- F((F))
classDef white fill:#fff,stroke:#666,color:#000
class A,B,C,D,E,F white
|
On choisit au hasard le sommet « A » |
flowchart LR
A((A)) --- B((B))
A --- C((C))
B --- D((D))
E((E)) --- F((F))
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef proc fill:#cce5ff,stroke:#3182bd,stroke-dasharray:5 5,color:#000
classDef white fill:#fff,stroke:#666,color:#000
class A blue
class B proc
class C proc
class B,D,E,F white
|
On marque (en bleu) le sommet A et on recherche ses descendants (ici B et C) |
flowchart LR
A((A)) --- B((B))
A --- C((C))
B --- D((D))
E((E)) --- F((F))
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef proc fill:#cce5ff,stroke:#3182bd,stroke-dasharray:5 5,color:#000
classDef white fill:#fff,stroke:#666,color:#000
class A,B,C blue
class D proc
class E,F white
|
On applique l'algorithme aux descendants (B et C), et on les marque dans la même couleur. |
flowchart LR
A((A)) --- B((B))
A --- C((C))
B --- D((D))
E((E)) --- F((F))
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef white fill:#fff,stroke:#666,color:#000
class A,B,C,D blue
class E,F white
|
Le sommet D est marqué mais n'a pas de descendants. |
flowchart LR
A((A)) --- B((B))
A --- C((C))
B --- D((D))
E((E)) --- F((F))
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef proc fill:#cce5ff,stroke:#3182bd,stroke-dasharray:5 5,color:#000
classDef white fill:#fff,stroke:#666,color:#000
class A,B,C,D blue
class E proc
class F white
|
On recherche au hasard un autre sommet parmi les sommets non marqués. Ce sera donc le sommet E. |
flowchart LR
A((A)) --- B((B))
A --- C((C))
B --- D((D))
E((E)) --- F((F))
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef orange fill:#f5a623,stroke:#d48000,color:#000
classDef proc fill:#ffe5cc,stroke:#d48000,stroke-dasharray:5 5,color:#000
class A,B,C,D blue
class E orange
class F proc
|
On colore le sommet E en orange, et on lui applique la même méthode. |
flowchart LR
A((A)) --- B((B))
A --- C((C))
B --- D((D))
E((E)) --- F((F))
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef orange fill:#f5a623,stroke:#d48000,color:#000
class A,B,C,D blue
class E,F orange
|
Tous les sommets sont colorés : l'algorithme s'arrête. |
Notre graphe a plusieurs propriétés :
En conséquence, il est nécessaire d'adapter l'algorithme. Il faut rappeler ainsi que chaque ligne de la liste d'adjacence correspond à un arc (liaison entre deux sommets). L'algorithme parcourt donc la liste d'adjacence, de la première à la dernière ligne.
flowchart LR
A((A)) --- B((B)) --- D((D))
A --- C((C))
E((E)) --- F((F))
G((G)) --- F
classDef gray fill:#b3cde3,stroke:#666,color:#000
class A,B,C,D,E,F,G gray
|
Arbre de départ : on sélectionne un arc au hasard (en réalité, il s'agit du premier arc présent dans la liste). |
flowchart LR
A((A)) --- B((B)) --- D((D))
A --- C((C))
E((E)) --- F((F))
G((G)) --- F
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef red fill:#e34a33,stroke:#b30000,color:#fff
classDef orange fill:#f5a623,stroke:#d48000,color:#000
classDef gray fill:#b3cde3,stroke:#666,color:#000
class A,C blue
class B,D red
class F,G orange
class E gray
|
Si cet arc n'est pas relié à un sommet étiqueté, colorier l'arc (et les sommets correspondants) d'une nouvelle couleur. Par exemple, les arcs A-C, B-D, F-G bénéficient d'une nouvelle couleur (cas 1). Dans les faits, ces 3 arcs seront examinés successivement. |
flowchart LR
A((A)) --- B((B)) --- D((D))
A --- C((C))
E((E)) --- F((F))
G((G)) --- F
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef red fill:#e34a33,stroke:#b30000,color:#fff
classDef orange fill:#f5a623,stroke:#d48000,color:#000
class A,C blue
class B,D red
class E,F,G orange
|
L'arc E-F est relié à un sommet déjà colorié (ici le sommet F, en orange). Il reprendra donc la couleur du sommet (cas 2). |
flowchart LR
A((A)) --- B((B)) --- D((D))
A --- C((C))
E((E)) --- F((F))
G((G)) --- F
linkStyle 0 stroke:#000,stroke-width:4px
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef red fill:#e34a33,stroke:#b30000,color:#fff
classDef orange fill:#f5a623,stroke:#d48000,color:#000
class A,C blue
class B,D red
class E,F,G orange
|
L'arc A-B est relié à deux sommets déjà coloriés (en bleu et en rouge). Dans ce cas… |
flowchart LR
A((A)) --- B((B)) --- D((D))
A --- C((C))
E((E)) --- F((F))
G((G)) --- F
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef red fill:#e34a33,stroke:#b30000,color:#fff
classDef orange fill:#f5a623,stroke:#d48000,color:#000
class A,B,C blue
class D red
class E,F,G orange
|
1. On colorie l'arc A-B avec l'une des couleurs (ici bleu). |
flowchart LR
A((A)) --- B((B)) --- D((D))
A --- C((C))
E((E)) --- F((F))
G((G)) --- F
classDef blue fill:#6baed6,stroke:#3182bd,color:#000
classDef orange fill:#f5a623,stroke:#d48000,color:#000
class A,B,C,D blue
class E,F,G orange
|
2. On « repeint » la couleur rouge par la couleur bleue (on transforme la couleur 2 en couleur 1). |
| (état final identique à l'étape précédente) | Tous les sommets sont coloriés : l'algorithme s'arrête. |
Ce rapport vise à établir, pour chaque parcelle cadastrale considérée comme urbanisée, l'usage de cette parcelle. En d'autres termes, l'objectif est de classer chaque parcelle dans une des catégories suivantes :
Pour rappel, le portail national contient deux autres usages (fer et routes). Ces deux usages sont cependant assignés via une méthodologie différente en post-traitement.
Pour analyser les déterminants de la consommation d'espaces, il est nécessaire de pouvoir faire la différenciation entre la consommation d'espaces destinée à l'habitat et celle destinée à l'activité, et ce sur l'intégralité des millésimes des Fichiers fonciers20. Dans ce cadre, et afin d'être comparable dans le temps, cette différenciation doit pouvoir se faire de la même manière sur tous les millésimes, actuels et à venir.
L'objectif unique de cette méthodologie est de permettre le calcul de cette consommation d'espaces.
En particulier, cette assignation a pour objectif de travailler en flux, c'est-à-dire de mettre en avant les changements entre catégories. En d'autres termes, si une parcelle à usage d'activité est considérée comme à usage d'habitat, mais n'évolue pas entre les millésimes, cela n'aura pas d'influence.
Cette méthodologie aurait donc besoin d'être adaptée si elle était utilisée pour d'autres usages (enrichissement d'un MOS, observation locale…).
La présente méthodologie se base sur des travaux antérieurs du Cerema, qui visaient à enrichir une occupation des sols, et en l'occurrence l'occupation des sols grande échelle de l'IGN, notamment pour redécouper des zones urbanisées en zones à usage d'habitat et à usage d'activité.
Cet enrichissement a été repris et adapté pour permettre le classement des parcelles.
En préalable de ce rapport, il est conseillé de lire les documents relatifs à ces deux travaux, à savoir :
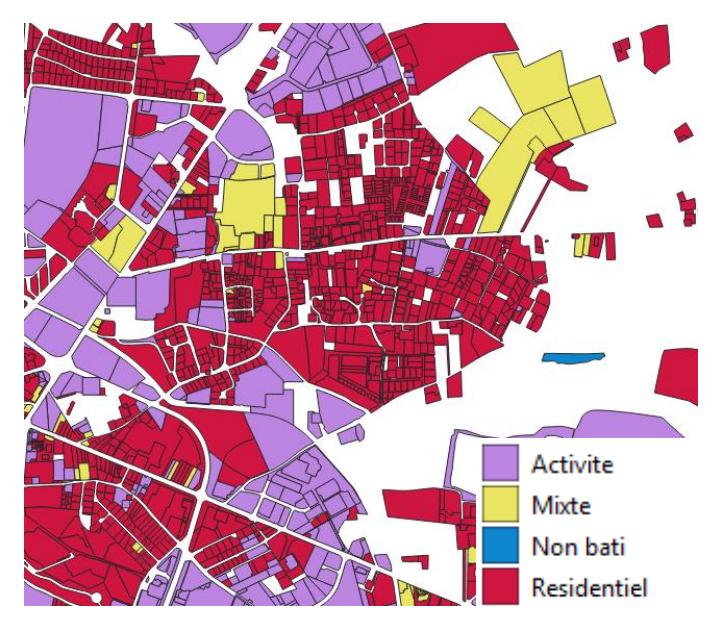
L'objectif est donc d'assigner un usage (habitat, activité ou mixte) à des parcelles urbanisées21. Cet usage se fera en fonction des locaux présents sur cette parcelle : une parcelle comportant un local à usage d'habitat sera classée elle-même comme « habitat » (Étape 1).
Cependant, certaines parcelles, urbanisées, ne portent pas de locaux. Il s'agit notamment ce que l'on nommera des « espaces associés » (parkings, jardins, voiries…). On assignera donc un usage à ces parcelles, et ce en fonction de l'usage des parcelles adjacentes (Étape 2).
La première partie du rapport portera donc sur l'assignation initiale : que considère-t-on comme « urbanisé » au sens des Fichiers fonciers, et comment définit-on une parcelle à usage « habitat » ou « activité » (Étape 1).
La deuxième partie se concentrera sur le processus d'affectation des espaces associés (Étape 2).
 Étape 1 : assignation des parcelles avec locaux selon leur usage. Les parcelles bleues sont les parcelles urbanisées, mais sans locaux (donc sans affectation)
Étape 1 : assignation des parcelles avec locaux selon leur usage. Les parcelles bleues sont les parcelles urbanisées, mais sans locaux (donc sans affectation)
Étape 2 : assignation de l’usage aux parcelles urbanisées ne portant pas de locaux
Ce traitement repose en grande partie sur la base de données des Fichiers fonciers22, issue des données de la taxe foncière. Le traitement est réalisé sur tous les millésimes disponibles23. Ces millésimes étant comparés par la suite, il est donc nécessaire de réaliser le traitement de manière comparable. Lors du traitement, certaines corrections sont réalisées à partir de la BDTopo de l'IGN.
Nous travaillerons sur les parcelles urbanisées au sens fiscal, c'est-à-dire dont l'attribut « dcntarti » est supérieur à 0. Nous ne travaillons ici qu'à l'échelle de la parcelle, et non à l'échelle de la TUP24, celle-ci n'étant pas présente dans les premiers millésimes des Fichiers fonciers.
On assigne à chaque parcelle une typologie en fonction de l'usage déclaré des locaux qu'elle contient. La typologie peut prendre 4 valeurs :
Chaque parcelle aura une et une seule affectation.
Pour chaque entité, on regarde le nombre de locaux à usage de logements ou d'activités. On distingue quatre cas :
Pour chacun des cas, si un des usages (activité ou résidentiel) est largement prépondérant sur l'autre, l'entité est affectée ainsi.
Pour rappel, le travail est réalisé sur la table des parcelles. On crée une nouvelle table, à l'échelle de la parcelle pour fournir, sur chaque entité :
Ces différentes informations permettront ainsi de bâtir les critères permettant de repérer l'affectation dominante.
Dans le décompte précédent, on exclut les locaux de type suivant :
En effet, la présence de ces locaux peut fausser l'affectation. En particulier, ils peuvent être présents sur de très grandes parcelles, qui sont ainsi affectées, à tort, comme de l'activité.
L'objet de cette première étape est de déterminer l'affectation de chaque parcelle.
En premier lieu, s'il y a uniquement des locaux résidentiels / d'activités, la parcelle est affectée en résidentiel / activités. Il en est de même si la parcelle ne possède pas de local (affectation en « non-bâti »). Il s'agit du cas 0, majoritaire.
S'il y a des parcelles avec des locaux résidentiels et d'activités, on distingue alors trois cas :
Ces cas sont évalués de manière croissante : si une parcelle possède un local industriel et un commerce, elle rentrera dans le cas 1.
Lors de cette étape, on calcule des scores permettant de déterminer si la parcelle est plutôt à usage d'habitation ou à usage d'activités. Ce calcul est réalisé pour tous les cas de la même manière. Par contre, l'utilisation qui en sera faite sera différente selon les cas.
Pour chaque parcelle, on détermine deux types de score :
Chaque parcelle aura ainsi un score entre 0 et 3 permettant de déterminer l'affectation. Si ce score normal ne suffit pas à déterminer de manière certaine l'affectation, on vérifiera le score de prédominance pour permettre quand même l'affectation.
Pour chaque parcelle, on calcule les éléments suivants :
Chaque parcelle aura ainsi un score compris entre 0 et 3, selon le nombre de critères qu'elle remplit, 3 signifiant une forte probabilité de prédominance de l'activité, 0 une faible probabilité. Les scores de 3 vont déboucher ainsi sur un classement de la parcelle en « activités », et de 0 en « mixte » ou « habitat » selon les cas.
Pour certains cas, les données présentées pour les activités économiques sont moins fiables. De même, les locaux d'activités peuvent ne correspondre qu'à une très faible portion de l'espace.
La parcelle est ainsi classée en « prédominance forte de l'activité » si elle répond à au moins un des critères suivants :
La parcelle est ainsi classée en « prédominance forte de l'habitat » si elle répond à au moins un des critères suivants :
Les scores normaux et de prédominance sont ainsi utilisés et combinés en fonction des différents cas déterminés à l'étape 1.1.
Les locaux qualifiés d'industriels, c'est-à-dire le cas 1, sont évalués par les impôts par méthode comptable26. Sans rentrer dans les détails, cela concerne les grands établissements industriels présents sur de grandes étendues. Par nature, les parcelles comportant ce type de locaux ont vocation à être classées à usage d'activités.
Cependant, les informations sur les locaux évalués par méthode comptable ne sont pas toujours fiables. Par exemple, comme la surface du local n'est pas utile au calcul de l'impôt, elle est donc souvent inscrite comme égale à 0.
On présume donc que la parcelle est par nature à usage d'activités, sauf si d'autres critères prouvent le contraire.
Le score normal est croisé avec le nombre de locaux d'habitation présents sur la parcelle :
Dans les autres cas, la parcelle est classée en « mixte ».
Les commerces avec boutique ont vocation à s'installer plutôt au sein d'un tissu mixte. On présume donc que la parcelle est par nature à usage mixte, sauf si d'autres critères montrent que l'activité est prépondérante.
Si le score normal est de 0 (très faible probabilité de prédominance de l'activité), la parcelle est classée en mixte. Si le score est de 3 (très forte probabilité de prédominance de l'activité), la parcelle est classée en « activité ».
Pour les cas intermédiaires, on regarde si on a une prédominance forte de l'activité (c'est-à-dire si l'activité correspond à plus de 95 % de la surface et/ou de la valeur locative). Si c'est le cas, la parcelle est classée en « activités ». Sinon, elle est classée en « mixte ».
En d'autres termes :
Le cas 3 correspond aux autres parcelles. Dans les faits, il s'agit souvent de parcelles avec des bureaux ou des locaux tertiaires. Cependant, il peut s'agir aussi d'un local d'habitation ou d'activité isolé dans un grand immeuble.
Il est donc nécessaire de tester 2 hypothèses :
Dans les autres cas, la parcelle sera considérée comme « mixte ».
Par rapport au cas 2, pour lequel le classement sera toujours au moins mixte, on étudie ici la possibilité que la parcelle soit aussi résidentielle.
Les Fichiers fonciers ne contiennent qu'un nombre réduit d'informations sur les bâtiments et équipements publics. À ce titre, il est nécessaire de redresser les affectations initiales à l'aide de sources de données extérieures.
Les premières étapes d'amélioration de l'affectation ont été réalisées à l'aide des seuls Fichiers fonciers. Cependant, pour cette étape, on ne peut se passer de données externes.
Les bâtiments publics ne sont pas toujours présents dans les Fichiers fonciers. Par exemple, une parcelle où il existe un collège public et des logements peut ne faire apparaître que les logements. Dans ce cas, la parcelle sera classée, à tort, comme « résidentielle », alors que sa vocation est plutôt tertiaire.
Pour le redressement, on croise la table obtenue dans les étapes précédentes avec différentes informations contenues dans la dernière version disponible de la BD Topo.

Passage de la parcelle portant la mairie de « Résidentiel » (à gauche) à « Activité » (à droite). Le point rouge correspond à la localisation de la mairie dans le PAI administratif de la BDTopo.
On utilise ainsi la couche BD Topo V3 « zone d'activité ou d'intérêt ». Certaines modalités, reliées à des équipements qui n'ont que peu d'influence sur l'affectation de la parcelle, sont toutefois exclues.
Après un certain nombre de tests, les lieux de cultes n'ont pas été utilisés. En effet, ils reprenaient aussi un certain nombre de petites chapelles, de croix, etc. La prise en compte de ces petits éléments créait ainsi artificiellement des zones tertiaires. On utilise ainsi les catégories « administratif ou militaire », « Science et enseignement », « Santé », mais en retirant les éléments dont la nature est « Borne » ou « maison forestière ».
On considère ainsi toutes les parcelles publiques27, qui croisent28 un point d'intérêt de la BD Topo. Si ces parcelles ont plus de 10 logements, elles sont classées en « Mixte ». Sinon, elles sont classées en « activité ».
À ce stade, nous possédons donc une liste de parcelles. Au sein de celles-ci :
L'objectif est donc d'arriver à affecter ces parcelles non-bâties mais urbanisées.
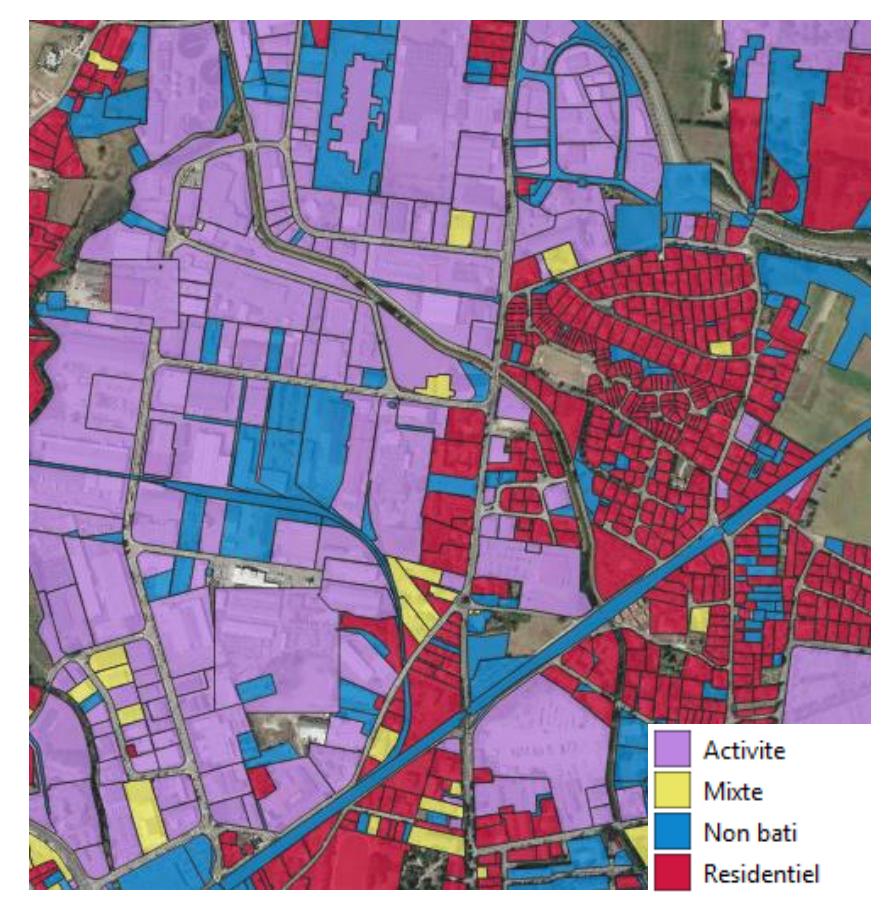
Les parcelles urbanisées sans local peuvent regrouper plusieurs cas :

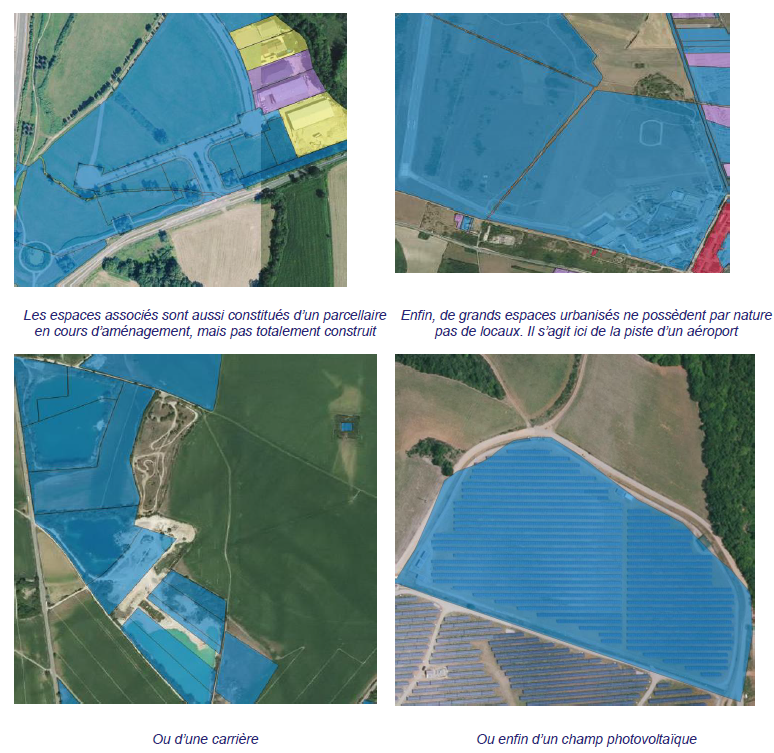
De nombreuses zones urbanisées sans local selon les Fichiers fonciers peuvent être affectées en étudiant les polygones affectés qui les entourent. Par exemple, un jardin non affecté entouré de parcelles résidentielles sera classé en « Résidentiel ». De la même manière, on pourra classer en « Activité » le parking d'une zone commerciale grâce au repérage des locaux commerciaux sur les parcelles environnantes.
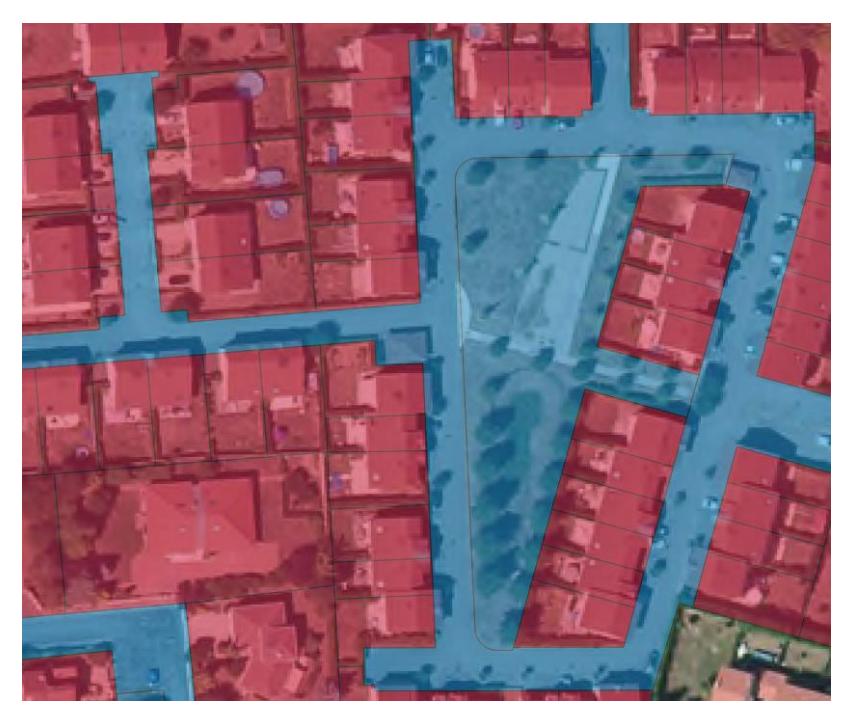
Pour chaque polygone de type « non affecté », un buffer de 0,5 m est appliqué afin de repérer géomatiquement les polygones affectés immédiatement voisins intersectés par des polygones, tout en s'affranchissant des problèmes de topologie imparfaite. Les polygones voisins ont été préalablement groupés par typologie commune, si bien que pour un polygone non affecté étudié, il va être possible de hiérarchiser l'influence des différents types le voisinant. Par exemple, le fait d'avoir groupé les différents polygones « Résidentiel » voisins va permettre de s'apercevoir qu'ils sont majoritaires par rapport au voisin « Activité ».
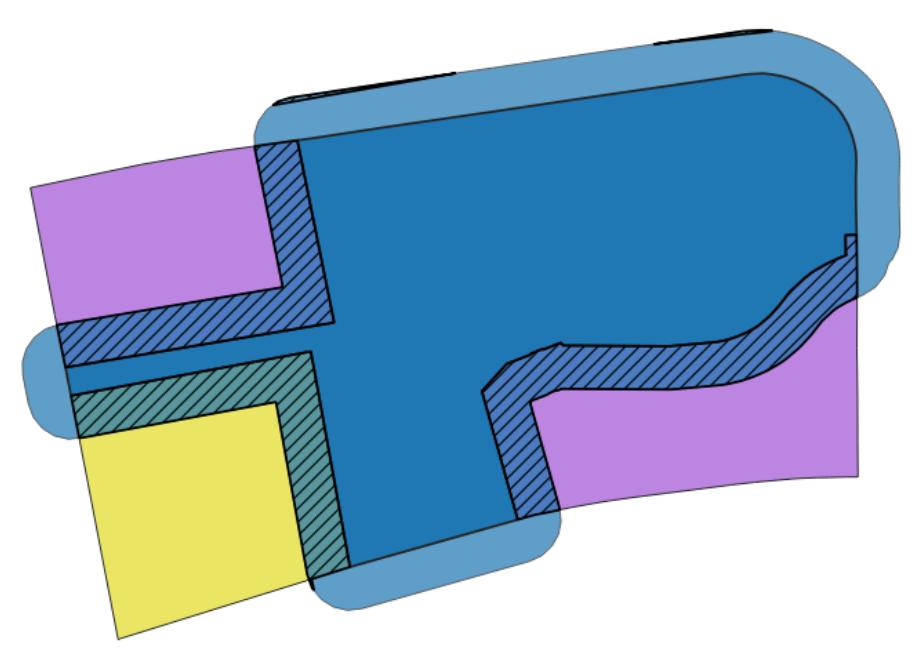
L'influence des typologies voisines du polygone « non affecté » est caractérisée par la longueur du contour commun entre chaque typologie et le polygone à affecter. Plus la longueur du contour commun entre le polygone et le type voisin est grande, plus le type voisin a de l'importance pour influencer la typologie du polygone « non affecté » à affecter. Sur le plan géomatique, cela revient à mesurer la surface d'intersection entre le buffer du polygone « non affecté » et chaque ensemble de polygones voisins de typologie identique.
Un polygone « non affecté » est affecté à l'aide d'un type voisin si (et seulement si) ces deux points sont vérifiés :
ET
OU
Le processus est mené de façon itérative jusqu'à ce qu'il n'y ait plus de polygones à affecter de la sorte.
NB : pour le premier point, il s'agit bien d'un seuil sur le contour touché par des typologies voisines, et non du contour total du polygone. Dans le cas d'un polygone en bordure d'une zone urbanisée, et donc possédant peu de voisin, ce seuil peut être difficile à atteindre. Le second point vise à s'assurer que le type voisin occupe effectivement une part substantielle du contour total du polygone.
Dans un second temps, on considère que dans des cas limites (seuil de 65 % pas tout à fait atteint), l'affectation en « Mixte » peut être privilégiée.
On effectue donc une deuxième affectation pour la seule typologie « Mixte ». On affecte un polygone « non affecté » en « Mixte » dès lors que le voisin de type « Mixte » occupe entre 40 et 65 % du contour du polygone « non affecté » touché par des polygones affectés.
Les critères à vérifier sont donc les deux suivants :
ET
OU
Le processus est mené de façon itérative jusqu'à ce qu'il n'y ait plus de polygones affectés de la sorte.
NB : pour le premier point, il s'agit bien d'un seuil sur le contour touché par des typologies voisines, et non du contour total du polygone. Dans le cas d'un polygone en bordure d'une zone, et donc possédant peu de voisin, ce seuil peut être très dur à atteindre. Le second point vise à s'assurer que le type voisin occupe effectivement une part substantielle du contour total du polygone.
Une dernière tentative d'affectation est réalisée afin d'assigner une classification à des polygones indéterminés, même lorsque le précédent tour d'affectation ne l'a pas permis. Il s'agit d'une affectation moins fiable, pour laquelle les seuils d'intersection (et donc les précautions d'usage liées) ont été supprimées.
Après cette étape, les polygones indéterminés restants ne seront que des polygones isolés (c'est-à-dire sans voisin).
Visuellement, on peut apprécier la disparition des surfaces « non affecté » au profit d’une typologie « logiquement » affectée, comme le montre la figure ci-dessous.
Comparaison de la carte avant l’étape 5 (à gauche) et après l’étape 5 (à droite).
À ce stade, une partie des parcelles est affectée. Dans les faits, il s'agit des parcelles immédiatement adjacentes à des parcelles affectées.
Cependant, nous avons choisi de ne travailler que sur les parcelles urbanisées, en excluant les autres. Dans les faits, cela donne un aspect très fragmenté aux polygones traités. Il n'est en effet pas rare qu'un chemin (non cadastré) sépare deux parcelles.
Exemples de polygones urbanisés non affectés avec un buffer de 0,5 m.
À ce stade, le taux d'affectation est encore bas. Il est donc nécessaire d'être plus permissif sur l'affectation, notamment en incluant une influence des parcelles plus lointaines.
La première affectation (ci-dessus) était réalisée en prenant un buffer de 0,5 m.
Le traitement est à réaliser plusieurs fois, avec des buffers de :
Ces affectations restent toutefois beaucoup plus rares que l'affectation par voisinage direct.
Affectation après un buffer de 10 m
Le traitement est réalisé sur la totalité des millésimes, et sur la totalité du territoire national. Chaque millésime et chaque département fait l'objet d'une table séparée. Les tables de sorties ont donc la structure suivante :
| Identifiant parcellaire | Surface totale | Affectation | Fiabilité |
|---|---|---|---|
| Parcelle1 | 1000 | Mixte | 0 |
| Parcelle2 | 2000 | Habitat | 10 |
| Parcelle3 | 500 | Habitat | 0,5 |
| Parcelle4 | 600 | Non affecté |
Chaque parcelle se voit assigner un score de fiabilité, égal au buffer utilisé :
Un indicateur permet en outre de savoir à quelle étape la parcelle a été affectée.
Au vu du nombre important de parcelles, le traitement est très gourmand en temps machine. Avec un serveur performant, il faut compter entre 30 et 40 heures par millésime (environ 3 semaines de traitement machine).
| Étape d'affectation | Nb parcelles | Surface (ha) | % parcelles | % surface |
|---|---|---|---|---|
| Étape 1 - Affectation directe (présence d'un local) | 276 400 066 | 47 704 993 | 58,07 % | 56,13 % |
| Étape 2 (buffer 0,5 m) - Affectation par parcelles adjacentes | 168 862 002 | 27 696 327 | 35,48 % | 32,59 % |
| Étape 2 (buffer 10 m) - Parcelles à moins de 10 m | 13 497 568 | 3 529 037 | 2,84 % | 4,15 % |
| Étape 2 (buffer 20 m) - Parcelles à moins de 20 m | 3 258 635 | 923 139 | 0,68 % | 1,09 % |
| Étape 2 (buffer 50 m) - Parcelles à moins de 50 m | 3 413 626 | 961 180 | 0,72 % | 1,13 % |
| Parcelles restant non affectées | 10 548 026 | 4 177 565 | 2,22 % | 4,92 % |
| Total | 465 431 897 | 84 992 241 | 100 % | 100 % |
Les résultats en termes d'affectation sont les suivants. On retrouve ainsi une majorité de parcelles à usage résidentiel. De son côté, le mixte est peu représenté.
Il faut toutefois noter qu'une part encore importante des parcelles reste non affectée. En pratique, il s'agit souvent de grandes activités sans locaux en dehors du tissu urbain (carrières, parc photovoltaïque…).
| Affectation | Nb parcelles | Surface (ha) | % parcelles | % surface |
|---|---|---|---|---|
| Résidentiel | 414 858 789 | 62 962 324 | 87,16 % | 74,96 % |
| Activité | 33 347 374 | 14 764 170 | 7,01 % | 17,58 % |
| Mixte | 17 225 734 | 2 088 182 | 3,62 % | 2,49 % |
| Non bâti | 10 548 026 | 4 177 566 | 2,22 % | 4,97 % |
| Total | 475 979 923 | 83 992 242 | 100 % | 100 % |
À ce stade, nous obtenons donc une liste des parcelles ainsi que de leur affectation. Cette liste permettra, dans un second temps, d'obtenir des informations sur l'affectation des parcelles urbanisées.
Nous avons en entrée 3 deltas, dont la somme est égale à 0. Nous souhaitons, en sortie, disposer de 6 flux.
Ces flux sont tous positifs.
Ce problème correspond au système d'équation suivant, Delta Urba, Delta NAF et Delta NC étant connues, les Flux étant les inconnues :
Δ Arti + Δ NAF + Δ NonCad = 0
∀ Flux, Flux ≥ 0 (1)
∀ i ∈ [Arti, NAF, NonCad], Δi = Σ Flux_j,i - Σ Flux_i,k (2)
(1) Tous les flux ≥ 0 [les flux sont positifs]
(2) Pour chaque delta, la somme des flux sortants moins les flux entrants = delta.
Par exemple :
Δ Urba = (NAF→Urba) + (NC→Urba) − (Urba→NAF) − (Urba→NC)
Δ NAF = (Urba→NAF) + (NC→NAF) − (NAF→Urba) − (NAF→NC)
Δ NC = (Urba→NC) + (NAF→NC) − (NC→Urba) − (NC→NAF)
Il s'agit ainsi d'un système d'équations linéaires sous contraintes typique d'un problème d'optimisation linéaire.
À ce stade, nous avons cependant un nombre d'inconnues trop important. Cela conduit à une infinité de solutions : il est ainsi nécessaire d'ajouter des hypothèses pour aboutir à une solution unique.
On postule ainsi que pour un îlot donné, il ne peut y avoir deux flux contraires. En d'autres termes, au sein d'un îlot, il ne peut y avoir à la fois un changement de NAF vers Urba et d'Urba vers NAF. Cela conduit à diviser par deux le nombre d'inconnues à rechercher, la moitié d'entre elles au moins étant systématiquement nulle.
Dans notre utilisation, et au vu de la granulométrie fine des îlots, cette hypothèse est peu contraignante. Cependant, poser cette hypothèse n'aurait pas pu être possible dans le cas de travaux à la commune, pour lesquelles il peut y avoir une partie de la commune qui consomme des espaces pendant qu'une autre partie se renature.
Cela simplifie le problème ainsi :
ΔArti+ΔNAF+ΔNonCad=0
ΔArti + ΔNAF + ΔNonCad = 0
Pour tout i dans {Arti, NAF, NonCad} :
Δi = Σ (Flux de j vers i) pour tous j ≠ i (2)
On perd la contrainte (1), mais on diminue le nombre d'inconnues. Au minimum, pour chaque paire de flux contraires (ex : NAF→Urba et Urba→NAF), l'un des deux sera systématiquement = 0.
À ce stade, les équations sont cependant encore liées. Nous avons donc encore deux équations pour 3 inconnues. À titre d'exemple, le système représenté sur le schéma s'écrit (attention aux signes !) :
−Flux ArtiNonCad + Flux NAFArti = 200 (1)
Flux NonCadNAF − Flux NAFArti = −300 (2)
Flux ArtiNonCad − Flux NonCadNAF = 100 (3)
L'équation (3) est clairement égale à − (1) − (2).
Il est nécessaire de postuler encore une nouvelle hypothèse pour obtenir une solution unique, à savoir que seuls des flux de même sens peuvent arriver dans une catégorie29. En conséquence, seuls deux flux seront différents de zéro (ou que l'un des flux sera égal à zéro)30.
De manière plus thématique, il s'agit de dire qu'une catégorie qui gagne de la surface ne peut en perdre en même temps : il ne peut à la fois y avoir un transfert de NAF vers Urba, et de Urba vers le non cadastré.
Une autre manière de formuler consiste à dire qu'entre plusieurs hypothèses de transformation, on privilégie la plus simple, à savoir que la parcelle ne change pas d'usage (ou se modifie le moins possible).
Ces éléments étant posés, on calcule le système précédent en distinguant 3 cas :
En conséquence, l'algorithme Kaver calculera, en sortie, 6 flux, dont au moins 4 seront égaux à 0.
L'algorithme Korange est une version plus complexe de Kaver : nous avons en entrée 3 Deltas, mais leur somme n'est pas égale à 0. Ainsi, Korange est utilisé pour déterminer les transferts entre habitat, activité et mixte : il peut y avoir une augmentation de la consommation d'espaces de chacun des postes, ainsi que des transferts entre ceux-ci.
Dans ce contexte, nous devons déterminer 9 flux : 6 flux internes, sur le même modèle que Kaver, mais aussi 3 flux externes.
À l'image de Kaver, Korange vise à répondre au problème suivant :
Trouver 9 flux (F_ext_hab, F_ext_act, F_ext_mix, F_hab→act, F_act→hab,
F_hab→mix, F_mix→hab, F_act→mix, F_mix→act) tels que :
Tous les flux ≥ 0
Δ Hab = F_ext_hab + F_act→hab + F_mix→hab − F_hab→act − F_hab→mix
Δ Act = F_ext_act + F_hab→act + F_mix→act − F_act→hab − F_act→mix
Δ Mix = F_ext_mix + F_hab→mix + F_act→mix − F_mix→hab − F_mix→act
avec Σ deltas = consommation nette totale ≠ 0
On réalise ici les mêmes postulats que pour Kaver, à savoir :
L'application des hypothèses supplémentaires de Kaver permet d'obtenir des solutions uniques dans les cas suivants :
Cas 1 : tous les deltas sont du même signe : dans ce cas, on ne retrouve que les deltas externes. Si Delta Act = 200, Delta Hab = 500 et Delta mix = 100, on aura donc uniquement des flux de création (3 flux externes). Il n'y a pas de flux internes (transferts entre catégories). Ce cas est de loin le plus répandu.
Cas 2 : un des deltas est positif, les deux autres sont négatifs, et le total est positif : Dans ce cas, l'apport de consommation d'espaces est assigné au delta positif. On applique ensuite Kaver pour déterminer les flux internes.
Les deux premiers cas peuvent se résoudre de manière non ambiguë avec les postulats de Kaver. Cependant, il existe un troisième cas pour lequel :
Pour ce cas, il existe plusieurs solutions pouvant répondre au problème, tout en respectant les contraintes.
Ce cas doit donc être traité à part. Dans ce cadre, il est souhaitable d'ajouter des contraintes. Plusieurs solutions peuvent exister :
Cependant, pour des raisons thématiques, il n'y a aucune raison de privilégier une catégorie ou un flux par rapport à d'autres. Dans ce cadre, ces solutions ne seront pas mises en place. Il est donc souhaitable de mettre en place une solution symétrique, par exemple selon les flux suivants :
Au final, les flux externes seront mis en avant, et resteront plus importants que les flux internes. Dans ce contexte, il est préférable de privilégier une approche équitable des flux externes.
L'algorithme prendra donc la somme des deltas, qu'il répartira équitablement entre les flux externes.
Dans certains cas, il n'est pas possible de répartir équitablement entre les catégories : c'est notamment le cas lorsque l'une des catégories est bien supérieure à l'autre.
Par exemple, si dans l’exemple précédent l’habitat est égal à +100, si l’on répartit de manière équivalente les flux entrants, on obtient le résultat suivant :
Par exemple, si dans l'exemple précédent l'habitat est égal à +100, si l'on répartit de manière équivalente les flux entrants, on obtient un résultat qui viole l'un de nos postulats, à savoir que chaque poste ne devait avoir que des flux du même signe : ici, le flux extérieur abonde l'habitat, et un flux interne vient le ponctionner.
On considère donc que les flux externes ne peuvent excéder le delta de la catégorie. Dans ce cas, la répartition sera donc :
Mesure de la consommation d'espaces à l'aide des Fichiers fonciers : définition, limites et comparaison avec d'autres sources, présent sur https://artificialisation.biodiversitetousvivants.fr/ ↩
www.datafoncier.cerema.fr ↩
Bocquet Martin, Cerema, Mesure de la consommation d'espaces induite par le logement social : Expérimentation en Hauts-de-France, juin 2023, disponible sur https://www.cerema.fr/fr/actualites/estimer-consommation-espace-induite-logement-social ↩
Article 192 de la LOI n° 2021-1104 du 22 août 2021 portant lutte contre le dérèglement climatique et renforcement de la résilience face à ses effets https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000043956924 ↩
Deux millésimes des Fichiers fonciers consécutifs, soient 2009-2011, 2011-2012, 2012-2013, etc. ↩
Un îlot est un ensemble d'une ou plusieurs parcelles stables dans le temps. L'îlot est défini précisément dans l'annexe 1 (traitement multi-millésime). ↩
En théorie, Surf Urba + Surf NAF = Surface totale. Sur ces rares parcelles, ce n'est pas le cas. ↩
Soit Urba + NAF + Non Cadastré (année N) = Urba + NAF + Non Cadastré (année N+1). En pratique, cela signifie que la somme des deltas sera égale à zéro. ↩
Pour donner un ordre d'idée de la surface concernée, au niveau national, 80 % des parcelles font moins de 5000 m². Cela est beaucoup plus important pour les parcelles qui subissent un changement, dont la quasi-totalité fait moins de 5000 m². ↩
C'est-à-dire que l'on ne peut par exemple avoir du NAF qui se transforme en urbanisé, et l'urbanisé qui se transforme en même temps en non-cadastré. ↩
C'est-à-dire que son flux NAF vers Urba est supérieur à zéro. ↩
C'est-à-dire que son flux Urba vers NAF est supérieur à zéro. Cependant, le terme « renaturation » n'est pas ici bien utilisé, le flux Urba vers NAF n'étant pas à proprement parler de la renaturation (cf. infra). ↩
http://bofip.impots.gouv.fr/bofip/5359-PGP.html#5359-PGP_La_parcelle_44 ↩
Le codage de la parcelle sur 14 caractères est fréquemment observé, mais n'est donc pas une convention. ↩
https://www.data.gouv.fr/fr/datasets/documents-de-filiation-informatises-dfi-des-parcelles/ ↩
De manière plus technique, il s'agit de reconstituer une structure de graphe, dont les parcelles Fichiers fonciers constituent les nœuds et les DFI des arcs (donc orientés). En particulier, le graphe résultant sera un graphe orienté acyclique, dont il s'agira d'extraire les composantes connexes. Il s'agit donc d'exploiter les apports de la théorie des graphes pour répondre au problème. ↩
La date de début correspond à la première date à laquelle on retrouve une correspondance entre un DFI et une parcelle. La date de fin est la dernière date. ↩
En reprenant la structure de base, c'est-à-dire celle d'un graphe orienté, on applique sur celui-ci un algorithme permettant de repérer les composantes connexes du graphe. ↩
2009, 2011, puis tous les ans jusque 2022 inclus, soient 13 millésimes. ↩
Soient 2009 puis chaque année depuis 2011. ↩
On considère, dans ce cadre, que les parcelles urbanisées sont celles classées comme urbanisées au sens des Fichiers fonciers, et donc dont l'attribut dcntarti est supérieur à 0. ↩
https://datafoncier.cerema.fr/ ↩
Soient 2009 puis annuellement à partir de 2011. ↩
La TUP est un ensemble de parcelles adjacentes de même propriétaire. L'intérêt de la TUP par rapport à la table parcellaire est présenté dans le guide de prise en main des Fichiers fonciers : https://datafoncier.cerema.fr/ressources/fichiers-fonciers ↩
Ce paragraphe est repris des deux études réalisées pour l'enrichissement d'une occupation des sols. ↩
Pour plus d'information : http://bofip.impots.gouv.fr/bofip/1443-PGP.html ↩
On utilise pour cela le champ TYPPROP (avant 2018) et le champ catpro3 (après 2018) des Fichiers fonciers. On considère comme publique une parcelle ayant au moins l'un des locaux appartenant à un propriétaire public. ↩
C'est-à-dire dont le point est situé à l'intérieur d'une parcelle. ↩
Il semblerait que cette condition soit équivalente à minimiser la somme des valeurs absolues des flux. Cette affirmation mériterait cependant d'être démontrée. ↩
Attention, cette condition est la conséquence du postulat, mais n'y est pas équivalente. ↩
L'usage « direct » est réservé aux parcelles urbanisées possédant un local. L'usage « extrapolé » est réservé aux parcelles urbanisées sans local : l'usage est assigné à partir de celui de ses voisins. Ce traitement est défini précisément dans l'annexe 2 (assignation de l'usage). ↩
En théorie, Surf Urba + Surf NAF = Surface totale. Sur ces rares parcelles, ce n'est pas le cas. ↩
La commune de Suzan (code INSEE 03904) est une enclave non délimitée au sein de La Bastide-de-Sérou (code INSEE 09042). Les services fiscaux, à l'inverse de l'INSEE, ne font pas la différence entre ces communes. ↩
Chézeaux (52124) est toujours rattachée à Varennes-sur-Amance (52504), Laneuville-à-Rémy (52266) est considérée comme rattachée à La Porte du Der (52331), Lavilleneuve-Au-Roi (52278) est toujours rattachée à Autreville-sur-la-Renne (52031), Culey (55138) est toujours rattachée à Loisey (55298), Avrecourt (52033) et Saulxures sont toujours considérés comme rattachés à Val-de-Meuse (52332). ↩
Soit « Mise à jour des Informations cadastrales », le nom de la base de données de la Direction générale des Finances publiques. ↩
Cerema, La densité de logement dans les opérations d'aménagement en extension urbaine - Cadrage méthodologique et données nationales, juin 2022, https://artificialisation.developpement-durable.gouv.fr ↩
Cerema, Mesure de la consommation d'espaces induite par le logement social : Expérimentation en Hauts-de-France, juin 2023, disponible sur : https://doc.cerema.fr/Default/doc/SYRACUSE/595520/ ↩
https://datafoncier.cerema.fr/usages/consommation-des-espaces-et-occupation-des-sols/enrichissement-ocsge-par-les-fichiers-fonciers ↩
https://datafoncier.cerema.fr/usages/consommation-des-espaces-et-occupation-des-sols/enrichissement-ocsge-ign-fichiers-fonciers-methode-approfondie-sur-grand-territoire ↩
On utilise ainsi la variable « dteloc ». ↩
Il s'agit d'une donnée fiscale, servant de base au calcul de l'impôt. À localisation identique, une forte valeur locative traduit souvent une grande surface. Il s'agit donc d'un indice pour savoir si la parcelle est essentiellement à usage résidentiel ou d'activités. ↩
Pour cela, on retire de la table des locaux les locaux dont le champ « cconlc » est égal à « AT », « UE » ou « CH », ainsi que les locaux dont « cconlc » est égal à « U » et « cconac » = '3512Z' (antennes relais). ↩
On utilise pour cela le code d'évaluation ccoeva égal à « A ». ↩
Ce seuil peut paraître haut, mais il faut rappeler qu'il n'est calculé que sur les zones sur lesquelles il y a au moins un local d'activités et un local professionnel. ↩
Ou alors un positif et deux négatifs. Cela est une conséquence directe du fait que la somme des deltas est égale à 0. ↩
Cela est aussi valable pour le cas opposé. ↩
